


INFORMATICA


1.INTRODUCCIÓN
1.1.ESTRUCTURA DE LA MAQUINA
1.1.1.PARTES DE UN COMPUTADOR
1.1.1.1.DISPOSITIVOS DE ENTRADA
1.1.1.2.DISPOSITIVOS DE SALIDA
1.1.1.3.MEMORIA AUXILIAR O SECUNDARIA
1.1.1.4.UNIDAD CENTRAL DE PROCESO
1.1.1.4.1.MEMORIA PRINCIPAL
1.1.1.4.2.UNIDAD DE CONTROL
1.1.1.4.3.UNIDAD ARITMÉTICO/LÓGICA
1.1.2.MEMORIA PRINCIPAL O CENTRAL
1.1.2.1.ESTRUCTURA DE LA MEMORIA PRINCIPAL
1.1.2.2.REPRESENTACIÓN DE LA INFORMACIÓN MEMORIA
1.1.2.2.1.NÚMEROS
1.1.2.2.2.CARACTERES
1.1.2.2.3.CÓDIGOS PARA CONTROL DE ERRORES
1.1.2.3.ACCESO A MEMORIA
1.1.2.3.1.PROCESO DE LECTURA
1.1.2.3.2.PROCESO DE ESCRITURA
1.1.2.4.CARACTERÍSTICAS
1.1.2.4.1.CAPACIDAD
1.1.2.4.2.TIEMPO DE ACCESO
1.1.2.4.3.VOLATILIDAD
1.1.2.4.4.COSTO
1.1.2.5.CLASIFICACIÓN
1.1.2.5.1.ROM
1.1.2.5.2.RAM
1.1.2.5.3.PROM
1.1.2.5.4.EPROM
1.1.2.6.ESTRUCTURA FÍSICA
1.1.2.6.1.NÚCLEOS DE FERRITA
1.1.2.6.2.INTEGRADAS
1.1.2.6.3.BURBUJAS MAGNÉTICAS
1.1.2.7.OTRAS (FOTODIGÍTALES, RAYO LÁSER, BIOLÓGICAS, ETC.)
1.1.3.UNIDAD DE CONTROL
1.1.3.1 SECUENCIA LÓGICA DE FUNCIONES
1. 1.3.1.1 LOCALIZACIÓN Y EXTRACCIÓN DEL EX DE LA INSTRUCCIÓN
1. 1.3.1.2 TRANSFERENCIAS DE MEMORIA PRINCIPAL LA UNIDAD DE CONTROL
1. 1.3.1.3 DEFINICIONES DE LA INSTRUCCIÓN
1. 1.3.1.4 EJECUCIÓN
1. 1.3.1.5 SUPERVISIÓN
1.1.3.2 ELEMENTOS
1. 1.3.2.1 RELOJ
1. 1.3.2.2 REGISTRÓ CONTADOR DE INSTRUCCIONES
1. 1.3.2.3 REGISTRO DE INSTRUCCIONES
1. 1.3.2.4 DECODIFICADOR
1. 1.3.2.5 SECUENCIADOR
1. 1.3.2.6 BANCO DE REGISTRO
1. 1.3.2.7 DESCENTRALIZACIÓN DE FUNCIONES Y NUEVAS TECNOLOGÍAS
1.1.4. UNIDAD ARITMÉTICO \LÓGICA
1.1.4.1 OPERACIONES BÁSICAS
1.1.4.2 UNIDAD ARITMÉTICA
1. 1.4.2.1 ARITMÉTICA BINARIA Y DE UNIDAD HERMÉTICA
1. 1.4.2.2 SISTEMAS PARA LAS OPERACIONES
1.1.4.3 UNIDAD LÓGICA
1. 1.4.3.1 OPERACIONES LÓGICAS
1. 1.4.3.2 LÓGICA DIGITAL DE UNIDAD LÓGICA
1. 1.5 BUSES
1. 1. 5. 1 DEFINICIONES
1.1.5.2 BUS DE DATOS
1. 1.5.2.1 4 BIT
1.1.5.2.2 8 BIT BUS
1.1.5.2.3 16 BIT BUS O ISA BUS
1.1.5.2.4 32 BIT O EISA BUS
1.1.5.2 BUS DIRECCIONES
1. 1.6 INSTRUCCIONES
1.1.6.1 FORMATOS
1.1.6.2 CÓDIGOS DE OPERACIÓN
1.1.6.2.1 OPERACIONES MÁS USUALES
1.1.6.3 DIRECCIONES
1.1.6.3. 1 INSTRUCCIONES DE UNA DIRECCIÓN
1. 1.6.3.2 INSTRUCCIONES DE DOS DIRECCIONES
1. 1.6.3.3 INSTRUCCIONES DE TRES DIRECCIONES
1. 1. 7 MEMORIAS VIRTUALES
1.1.7.1 NECESIDAD DE LA MEMORIA VIRTUAL
1.1.7.2 PAGINACIÓN
1.1.7.3 TABLAS DE PÁGINAS
1.1.7.4 CARGAS DE PÁGINAS
1. 1.7.4.1 MÉTODO FIFO
1. 1.7.4.2 MÉTODO LRU
1. 1.7.4.3 BIT DE ENSUCIADO
1. 1.7.4.4 FRAGMENTACIÓN
1.2 EVOLUCIÓN DE LOS COMPONENTES DE UN SISTEMA DE PROGRAMACIÓN
1. 2. 1 ENSAMBLADORES
1. 2. 2 CARGADORES
1. 2. 3 MARCOS
1. 2.4 COMPILADORES
1. 2. 5 SISTEMAS FORMALES
1.3 EVOLUCIÓN DE LOS SISTEMAS OPERATIVOS
1.4 EL SISTEMA OPERATIVO DESDE EL PUNTO DE VISTA DEL USUARIO
1.4.1 FUNCIONES
1. 4. 2 LENGUAJES DE CONTROL DE LOTES
1.4.3 RECURSOS
2. ESTRUCTURA DE LA MÁQUINA. LENGUAJE ENSAMBLADOS
2. 1 ESTRUCTURA GENERAL DE LAS MÁQUINAS
2.1. 1 COMO FAMILIARIZARNOS CON UNA MÁQUINA NUEVA
2.1.1.1 MEMORIA
2.1.1.2 REGISTROS
2.1.1.3 DATOS
2.1.1.4 INSTRUCCIONES
2.1.1.5 CARACTERÍSTICAS ESPECIALES
2. 1. 2 ESTRUCTURAS DE ALGUNAS MÁQUINAS
2.2 LENGUAJE DE MÁQUINAS
2.2.1 POR EL CAMINO LARGO, EN CICLOS
2. 2. 2 MODIFICACIONES DE LAS DIRECCIONES CON EL USO DE INSTRUCCIONES COMO DATOS
2. 2. 3 MODIFICACIÓN DE LAS DIRECCIONES CON EL USO DE REGISTROS ÍNDICES
2.2. 4 FORMACIÓN DE CICLOS
2. 3 LENGUAJE ENSAMBLADOR
2. 3. 1 UN PROGRAMA EN LENGUAJE ENSAMBLADOR
2. 3. 2 EJEMPLO CON LITERALES
3. ENSAMBLADORES
3. 1 PROCEDIMIENTO GENERAL DE DISEÑO
3. 2 DISEÑO DE ENSAMBLADOR
3. 2. 1 PLANTEAMIENTO DEL PROBLEMA
3. 2.2 ESTRUCTURA DE LOS TRATOS
3. 2.3 ESTRUCTURA DE LAS BASES DE DATOS
3. 2. 4 ALGORITMOS
3. 2. 5 ORGANIZACIÓN MODULAR
3. 3 PROCESAMIENTO DE TABLAS: BÚSQUEDA Y CLASIFICACIONES
3.3. 1 BÚSQUEDA LINEAL
3. 3.2 BÚSQUEDA BINARIA
3. 3.3 CLASIFICACIÓN
3. 3. 4 BÚSQUEDA A AZAR
4. MACROLENGUAJES Y MACROPROCESADORES
4.1 MACROINSTRUCCIONES
4.2 PARTICULARIDADES DE LOS MACROS
4.2.1 ARGUMENTOS DE MACROINSTRUCCION
4.2.2 EXPANSION CONDICIONAL DE MACROS
4.2.3 MACROLLAMADAS DENTRO DE MACROINSTRUCCIONES
4.2.4 MACROINSTRUCCIONES QUE DEFINEN MACROS
4.3. IMPLEMENTACION
4.3.1 IMPLEMENTACION RESTRINGIDA. ALGORITMO DE DOS PASOS
4.3.2 UN ALGORITMO DE UNA POSADA
4.3.3 IMPLEMENTACION DE MACROLLAMADAS DENTRO DE MACROS
4.3.4 IMPLEMENTACION DENTRO DE UN ENSAMBLADOR
5. CARGADORES
5.1 ESQUEMA DE CARGA
5.1.1 CARGADORES "COMPILE Y TRANSFERENCIA"
5.1.2 ESQUEMA GENERAL DE CARGA
5.1.3 CARGADORES ABSOLUTOS
5.1.4 ENCADENAMIENTO DE SUBRUTINAS
5.1.5 CARGADORES
5.1.6 REASINADORES
5.1.7 CARGADORES DE ENCADENAMIENTO DIRECTO
5.1.8 OTROS SISTEMAS DE CARGA
5.1.9 ENCUADERNADORES, CARGADORES, ENCADENADORES "OVERLAYS"
5.1.10 ENCUADERNADORES DINAMICOS
5.2 DISEÑO DE UN CARGADOR ABSOLUTO
5.3 DISEÑO DE UN CARGADOR DE ENCADENAMIENTO DIRECTO
5.3.1 PLANTEAMIENTO DEL PROBLEMA
5.3.2 ESPECIFICACION DE LAS ESTRUCTURAS DE DATOS
5.3.3 FORMATO DE LA BASE DE DATOS
5.3.4 ALGORITMOS
6. LENGUAJES DE LA PROGRAMACION
6.1 IMPORTANCIA DE LOS LENGUAJES DE ALTO NIVEL
6.2 PECULIARIDADES DE UN LENGUAJE DE ALTO NIVEL
6.3 TIPOS DE DATOS Y ESTRUCTURA DE DATOS
6.3.1 SERIES DE CARACTERES
6.3.2 SERIES DE BITS
6.3.3 OPERADORES BOOLEANOS
6.3.4 ESTRUCTURA DE DATOS
6.4 ASIGNACION DE ALMACENAMIENTO Y ALCANCE DE NOMBRES
6.4.1 CLASE DE ALMACENAMIENTO
6.4.2 ESTRUCTURA DE BLOQUES
6.5 FLEXIBILIDAD DE ACCESO
6.5.1 INDICADOR
6.5.2 VARIABLES DE ROTULO Y COLECCIONES DE ROTULOS
6.6 MODULARIDAD FUNCIONAL
6.6.1 PROCEDIMIENTOS
6.6.2 RECLUSION
6.7 OPERACION ASINCRONA
6.7.1 CONDICIONES
6.7.2 SEÑALES
6.7.3 MULTIAREA
6.8 EXTENSIBILIDAD Y MACROS DE TIEMPO DE COMPILACION
6.6.-MODULARIDAD FUNCIONAL
6.6.1.-PROCEDIMIENTOS
6.6.2.-RECLUSION
6.7.-OPERACIÓN ASÍNCRONA
6.7.1.-CONDICIONES
6.7.2.-SEÑALES
6.7.3.-MULTIAREA
6.8.-EXTENSIBILIDAD Y MACROS DE TIEMPO DE COMPILACIÓN
7.-INTRODUCCCION A LOS SISTEMAS FORMALES Y LOS LENGUAJES DE PROGRAMACION
7.1.-USO DE LOS SISTEMAS FORMALES EN LOS LENGUAJES DE PROGRAMACIÓN
7.1.1.-ESPECIFICACIONES DE LENGUAJES
7.1.2.-COMPILADORES SINTÁCTICOS
7.1.3.-ESTUDIOS DE COMPLEJIDAD DE ESTRUCTURAS
7.1.4.-ANALISIS DE ESTRUCTURAS
7.2.-ESPECIFICACION FORMAL
7.2.1.-ESPECIFICACION FORMAL
7.2.2.-DESARROLLO DE UNA ESPECIFICACIÓN FORMAL
7.3.-GRAMATICAS FORMALES
7.3.1.-EJEMPLO DE GRAMÁTICAS FORMALES
7.3.2.-LA DERIVACIÓN DE SENTENCIAS
7.3.3.-FORMAS SENTÉNCIALES Y SENTENCIARES
7.4.-JERARQUIAS DE LENGUAJES
7.5.-FORMAS DE BACKUN-NAUR. FORMA NORMAL DE BACKUS-BNF
7.6.-SISTEMAS CANÓNICOS
7.6.1.-ESPECIFICACION DE SINTAXIS
7.6.2.-ESPECIFICACION DE UNA TRADUCCIÓN
7.6.3.-ALGORITMO DE RECONOCIMIENTOS Y TRADUCCIÓN
7.7.-SISTEMAS CANÓNICOS Y SISTEMAS FORMALES
8.COMPILADORES
8.1. PLANTEO DEL PROGRAMA
8.1.1. RECONOCIMIENTO DE LOS ELEMENTOS BASICOS
8.1.2. RECONOCIMIENTO DE LAS UNIDADES SINTACTICAS E INTERPRETACION DEL SIGNIFICADO
8.1.3. FORMAS INTERMEDIAS
8.1.4. ASIGNACION DEL CODIGO
8.1.5. MODELO GENERALIZADO DEL COMPILADOR
8.2. FASES DEL COMPILADOR
8.2.1. FASE LEXICA
8.2.2. FASE DE INTERPTRETCION
8.2.3. OPTIMIZACION
8.2.4. ASIGNACION DEL ALMACENAMIENTO
8.2.5. GENERACION DEL CODIGO
8.2.6. FASE DE EMSAMBLE
8.2.7. PASADAS DE UN COMPILADOR
8.2.8. SOBRE LA PARTE 3
8.3. ESTRUCTURA DE DATOS
8.3.1. PLANO DE PROGRAMA
8.3.2. IMPLEMENTACION
8.4. ENUNCIADOS DERECURSION, LLAMADA Y RETORNO
8.5. CLASES DE ALMACENAMIENTO Y SU USO
8.5.1. ALMACENAMIENTO ESTATICO
8.5.2. ALMACENAMIENTO AUTOMATICO
8.5.3. ALMACENAMIENTO CONTROLADO EXTERNO
8.5.4. ALMACENAMIENTO CONTROLADO INTERNO
8.5.5. ALMACENAMIENTO BASADO
8.6. EJECUCION
8.7. ESTRUCTURAS DEL BLOQUE
8.8. ENUNCIADOS GO TO NO LOCALES
8.9. INTERRUPCIONES
8.10. INDICADORES (POINTERS)
INTRODUCCION
Uno de los principales mecanismos de comunicación entre un ordenador y una persona viene dado por el envío y recepción de mensajes de tipo textual: el usuario escribe una orden mediante el teclado, y el ordenador la ejecuta devolviendo como resultado un mensaje informativo sobre las acciones llevadas a cabo.
Aunque la evolución de los ordenadores se encuentra dirigida actualmente hacia el empleo de novedosas y ergonómicas interfaces de usuario (como el ratón, las pantallas táctiles, las tabletas gráficas, etc.), podemos decir que casi todas las acciones que el usuario realiza sobre estas interfaces se traducen antes o después a secuencias de comandos que son ejecutadas como si hubieran sido introducidas por teclado. Por otro lado, y desde el punto de vista del profesional de la Informática, el trabajo que éste realiza sobre el ordenador se encuentra plagado de situaciones en las que se produce una comunicación textual directa con la máquina: utilización de un intérprete de comandos (shell), construcción de ficheros de trabajo por lotes, programación mediante diversos lenguajes, etc. Incluso los procesadores de texto como WordPerfect y MS Word almacenan los documentos escritos por el usuario mediante una codificación textual estructurada que, cada vez que se abre el documento, es reconocida, recorrida y presentada en pantalla. Por todo esto, ningún informático que se precie puede esquivar la indudable necesidad de conocer los entresijos de la herramienta que utiliza durante su trabajo diario y sobre la que descansa la interacción hombre-máquina: el traductor.
La teoría de lenguajes de programación es una rama de la informática que se encarga del diseño, implementación, análisis, caracterización y clasificación de lenguajes de programación y sus características. Es un campo multi-disciplinar, dependiendo tanto de (y en algunos casos afectando) matemáticas, ingeniería del software, lingüística, e incluso ciencias cognitivas. Es una rama bien reconocida de la informática, y a fecha de 2006, un área activa de investigación, con resultados publicados en un gran número de revistas dedicadas a la PLT, así como en general en publicaciones de informática e ingeniería.La mayoría de los programas de los estudiantes universitarios de informática requieren trabajar en este tema.
Un símbolo no oficial de la teoría de lenguajes de programación es la letra griega lambda en minúsculas. Este uso deriva del cálculo lambda, un modelo computacional ampliamente usado por investigadores de lenguajes de programación. Muchos textos y artículos sobre programación y lenguajes de programación utilizan lambda de una u otra manera. Ilustra la portada del texto clásico Estructura e Interpretación de Programas de Ordenador, y el título de muchos de los llamados Artículos Lambda, escritos por Gerald Jay Sussman y Guy Steele, creadores del lenguaje de programación Scheme. Un sitio muy conocido sobre teoría de lenguajes de programación se llama Lambda the Ultimate (Lambda el primordial), en honor al trabajo de Sussman y Steele.
TEMARIO
ESTRUCTURA DE LA MAQUINA
Un computador se divide fundamentalmente en dos partes: el Hardware y el Software. El hardware es la parte física del computador, la parte tangible; es decir aquello que podemos tocar del computador. El software es la parte lógica del computador, es decir el conjunto de instrucciones que le ordenan al hardware que tarea debe realizar.
Arquitectura del Hardware
El Hardware es la parte tangible del computador, aquella que se puede palpar. Los componentes Hardware se refiere a las partes físicas y accesorios complementarios que componen la Unidad Central de Procesamiento (CPU) así como a los dispositivos externos, tales como, monitor, impresora, teclado, mouse, cornetas. Si vemos el computador como una estructura de hardware, notaremos que está constituido por dispositivos, que clasificaremos según la función que desempeñen. De acuerdo a esta clasificación tendremos:
-
Dispositivos de Entrada.
-
Dispositivos de Salida.
-
Dispositivos de Comunicación.
-
Dispositivos de Almacenamiento.
-
Dispositivos de Cómputo.
PARTES DE UN COMPUTADOR
La computadora le sirve al hombre como una valiosa herramienta para realizar y simplificar muchas de sus actividades. En sí es un dispositivo electrónico capaz de interpretar y ejecutar los comandos programados para realizar en forma general las funciones de:
-
Operaciones de entrada al ser receptora de información.
-
Operaciones de cálculo, lógica y almacenamiento.
-
En la actualidad las computadoras tienen aplicaciones más prácticas, porque sirve no solamente para Computar y calcular, sino para realizar múltiples procesos sobre los datos proporcionados, tales como clasificar u ordenar, seleccionar, corregir y automatizar, entre otros, por estos motivos en Europa su nombre que más común es el de ordenador.
-
Operaciones de salida al proporcionar resultados de las operaciones antecedentes.
DISPOSITIVOS DE ENTRADA
Los dispositivos de entrada son aquellos al través de los cuales se mandan datos a la unidad central de procesos, por lo que su función es eminentemente emisora. Algunos de los dispositivos de entrada más conocidos son el teclado, el manejador de discos magnéticos, la reproductora de cinta magnética, el ratón, el digitalizador (scanner), el lector óptico de código de barras y el lápiz óptico entre otros.
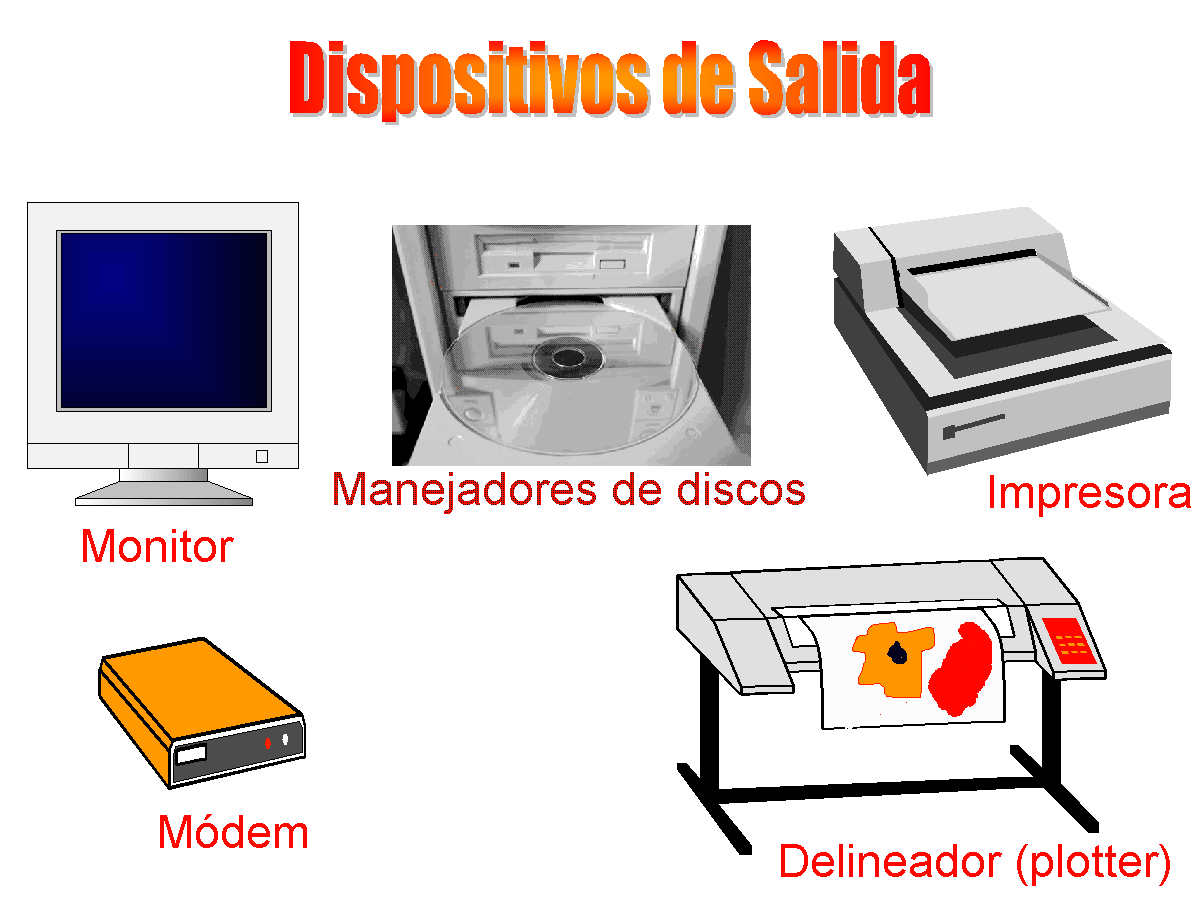
DISPOSITIVOS DE SALIDA
Dispositivos de salida (DS)
Los dispositivos de salida son aquellos que reciben información de la computadora, su función es eminentemente receptora y por ende están imposibilitados para enviar información. Entre los dispositivos de salida más conocidos están: la impresora (matriz, cadena, margarita, láser o de chorro de tinta), el delineador (plotter), la grabadora de cinta magnética o de discos magnéticos y la pantalla o monitor.
MEMORIA AUXILIAR O SECUNDARIA
El almacenamiento secundario (memoria secundaria, memoria auxiliar o memoria externa) es el conjunto de dispositivos (aparatos) y medios (soportes) de almacenamiento, que conforman el subsistema de memoria de una computadora, junto a la memoria principal.
No deben confundirse las "unidades o dispositivos de almacenamiento" con los "medios o soportes de almacenamiento", pues los primeros son los aparatos que leen o escriben los datos almacenados en los soportes.
La memoria secundaria es un tipo de almacenamiento masivo y permanente (no volátil), a diferencia de la memoria RAM que es volátil; pero posee mayor capacidad de memoria que la memoria principal, aunque es más lenta que ésta.
El proceso de transferencia de datos a un equipo de cómputo se le llama "procedimiento de lectura". El proceso de transferencia de datos desde la computadora hacia el almacenamiento se denomina "procedimiento de escritura".
En la actualidad para almacenar información se usan principalmente tres 'tecnologías':
-
Magnética (ej. disco duro, disquete, cintas magnéticas);
-
Óptica (ej. CD, DVD, Blu-ray Disc, etc.)
- Algunos dispositivos combinan ambas tecnologías, es decir, son dispositivos de almacenamiento híbridos, por ej., discos Zip. -
Memoria Flash (Tarjetas de Memorias Flash y Unidades de Estado sólido SSD)
UNIDAD CENTRAL DE PROCESO
Central Processing Unit (CPU, Unidad Central de Procesamiento) también llamado procesador, es el componente principal del ordenador y otros dispositivos programables, que interpreta las instrucciones contenidas en los programas y procesa los datos. Las CPU proporcionan la característica fundamental del ordenador digital (la programabilidad) y son uno de los componentes necesarios encontrados en los ordenadores de cualquier tiempo, junto con la memoria principal y los dispositivos de entrada/salida. Se conoce como microprocesador el CPU que es manufacturado con circuitos integrados. Desde mediados de los años 1970, los microprocesadores de un solo chip han reemplazado casi totalmente todos los tipos de CPU y hoy en día, el término "CPU" es aplicado usualmente a todos los microprocesadores. La expresión "unidad central de proceso" es, en términos generales, un dispositivo lógico que pueden ejecutar complejos programas de ordenador. Esta amplia definición puede fácilmente ser aplicada a muchos de los primeros ordenadores que existieron mucho antes que el término "CPU" estuviera en amplio uso. Sin embargo, el término en sí mismo y su acrónimo han estado en uso en la industria de la Informática por lo menos desde el principio de los años 60. La forma, el diseño y la implementación de las CPU ha cambiado drásticamente desde los primeros ejemplos, pero su operación fundamental ha permanecido bastante similar. Las primeras CPU fueron diseñados a la medida como parte de un ordenador más grande, generalmente un ordenador único en su especie. Sin embargo, este costoso método de diseñar las CPU a la medida, para una aplicación particular, ha desaparecido en gran parte y se ha sustituido por el desarrollo de clases de procesadores baratos y estandarizados adaptados para uno o muchos propósitos. Esta tendencia de estandarización comenzó generalmente en la era de los transistores discretos, ordenadores centrales y microordenadors y fue acelerada rápidamente con la popularización del circuito integrado (IC), éste ha permitido que sean diseñados y fabricados CPU más complejas en espacios pequeños (en la orden de milímetros). Tanto la miniaturización como la estandarización de las CPU han aumentado la presencia de estos dispositivos digitales en la vida moderna mucho más allá de las aplicaciones limitadas de máquinas de computación dedicadas. Los microprocesadores modernos aparecen en todo, desde automóviles, televisores, neveras, calculadoras, aviones, hasta teléfonos móviles o celulares, juguetes, entre otros. En la actualidad muchas personas llaman CPU al armazón del computador (torre), confundiendo de esta manera a los principiantes en el mundo de la computación.
MEMORIA PRINCIPAL
La memoria principal o primaria,"Memoria Central ", es aquella memoria de un ordenador, la memoria es apta para 1200 gb, prácticamente la mejor , es un dispositivo donde se almacenan temporalmente tanto los datos como los programas que la CPU está procesando o va a procesar en un determinado momento. Por su función, es una amiga inseparable del microprocesador, con el cual se comunica a través de los buses de datos. Por ejemplo, cuando la CPU tiene que ejecutar un programa, primero lo coloca en la memoria y después lo empieza a ejecutar. lo mismo ocurre cuando necesita procesar una serie de datos; antes de poder procesarlos los tiene que llevar a la memoria principal.
Esta clase de memoria es volátil, es decir que, cuando se corta la energía eléctrica, se borra toda la información que estuviera almacenada en ella.
Por su función, la cantidad de memoria RAM de que disponga una computadora es una factor muy importante; hay programas y juegos que requieren una gran cantidad de memoria para poder usarlos. otros andarán más rápido si el sistema cuenta con más memoria RAM.
La memoria Caché: dentro de la memoria RAM existe una clase de memoria denominada Memoria Caché que tiene la característica de ser más rápida que las otras, permitiendo que el intercambio de información entre el procesador y la memoria principal sea a mayor velocidad.
La estructura de la memoria principal ha cambiado en la historia de las computadoras. Desde los años 1980 es prevalentemente una unidad dividida en celdas que se identifican mediante una dirección. Está formada por bloques de circuitos integrados o chips capaces de almacenar, retener o "memorizar" información digital, es decir, valores binarios; a dichos bloques tiene acceso el microprocesador de la computadora.
La MP se comunica con el microprocesador de la CPU mediante el bus de direcciones. El ancho de este bus determina la capacidad que posea el microprocesador para el direccionamiento de direcciones en memoria.
En algunas oportunidades suele llamarse "memoria interna" a la MP, porque a diferencia de los dispositivos de memoria secundaria, la MP no puede extraerse tan fácilmente por usuarios no técnicos.
La MP es el núcleo del sub-sistema de memoria de una computadora, y posee una menor capacidad de almacenamiento que la memoria secundaria, pero una velocidad millones de veces superior.
UNIDAD DE CONTROL
La unidad de control (UC) es uno de los tres bloques funcionales principales en los que se divide una unidad central de procesamiento (CPU). Los otros dos bloques son la unidad de proceso y el bus de entrada/salida.
Su función es buscar las instrucciones en la memoria principal, decodificarlas (interpretación) y ejecutarlas, empleando para ello la unidad de proceso.
Existen dos tipos de unidades de control, las cableadas, usadas generalmente en máquinas sencillas, y las microprogramadas, propias de máquinas más complejas. En el primer caso, los componentes principales son el circuito de lógica secuencial, el de control de estado, el de lógica combinacional y el de emisión de reconocimiento de señales de control. En el segundo caso, la microprogramación de la unidad de control se encuentra almacenada en una micromemoria, a la cual se accede de manera secuencial para posteriormente ir ejecutando cada una de las microinstrucciones. Estructura del computador: Unidad aritmético-lógica (UAL o ALU por su nombre en inglés, Arithmetic Logic Unit): aquí se llevan a cabo las operaciones aritméticas y lógicas.
Por otra parte esta la unidad de control, que fue históricamente definida como una parte distinta del modelo de referencia de 1946 de la Arquitectura de von Neumann. En diseños modernos de computadores, la unidad de control es típicamente una parte interna del CPU y fue conocida primeramente como arquitectura Eckert-Mauchly. Memoria: que almacena datos y programas. Dispositivos de entrada y salida: alimentan la memoria con datos e instrucciones y entregan los resultados del cómputo almacenados en memori. Buses: proporcionan un medio para transportar los datos e instrucciones entre las distintos y pequeños que la memoria principal (los registros), constituyen la unidad central de procesamiento (UCP o CPU por su nombre en inglés: Central Processing Unit).
UNIDAD ARITMÉTICO/LÓGICA
En computación, la unidad aritmético lógica, también conocida como ALU (siglas en inglés de arithmetic logic unit), es un circuito digital que calcula operaciones aritméticas (como suma, resta, multiplicación, etc.) y operaciones lógicas (si, y, o, no), entre dos números.
Muchos tipos de circuitos electrónicos necesitan realizar algún tipo de operación aritmética, así que incluso el circuito dentro de un reloj digital tendrá una ALU minúscula que se mantiene sumando 1 al tiempo actual, y se mantiene comprobando si debe activar el sonido de la alarma, etc.
Por mucho, los más complejos circuitos electrónicos son los que están construidos dentro de los chips de microprocesadores modernos. Por lo tanto, estos procesadores tienen dentro de ellos un ALU muy complejo y potente. De hecho, un microprocesador moderno (y losmainframes) puede tener múltiples núcleos, cada núcleo con múltiples unidades de ejecución, cada una de ellas con múltiples ALU.
Muchos otros circuitos pueden contener en el interior una unidad aritmético lógica: unidades de procesamiento gráfico como las que están en las GPU modernas, FPU como el viejo coprocesador matemático 80387, y procesadores digitales de señales como los que se encuentran en tarjetas de sonido, lectoras de CD y los televisores de alta definición. Todos éstos tienen en su interior varias ALU potentes y complejas.

MEMORIA PRINCIPAL O CENTRAL
La función de la memoria principal es almacenar datos e instrucciones de programa de forma temporal. Es estación obligada en todas las operaciones de entrada y salida y, por supuesto, de los resultados parciales o finales del proceso.
La memoria esta estructurada en forma de una colección de celdas, en cada una de las cuales cabe una unidad especifica de información: octetos o palabras. El contenido de cada una de las posiciones de memoria podrá ser bien dato o instrucción. Cada celda tiene asignada una posición relativa con respecto a un origen, cuyo valor numérico constituye la dirección de la misma y que no se encuentra almacenado en ella.
Con la misión de garantizar estabilidad y seguridad en las operaciones, la dirección y datos deben mantenerse en registros durante ese tiempo. En la memoria nos encontramos con:
Registro de dirección de memoria en la que almacena temporalmente la dirección sobre la que efectúa la selección.
Registro de Información de memoria en donde se almacena el dato durante las fases de lectura o escritura en la celda señalada por el registro anterior.
ESTRUCTURA DE LA MEMORIA PRINCIPAL
La estructura de la memoria en una computadora abarca varios dispositivos que almacenan datos y aplicaciones, que son procesados por la unidad central de procesamiento o CPU. El marco de la memoria tiene un impacto significativo en la velocidad de cualquier sistema informático, porque los procesadores funcionan a un ritmo mucho más rápido que la memoria ordinaria. Con los años, los diseñadores han desarrollado metodologías de memoria que son eficientes y rentables.
REPRESENTACIÓN DE LA INFORMACIÓN MEMORIA
CODIGO BCD:
El código BCD (decimal codificado en binario) utiliza un cuarteto o nibble (4bits) para la representación de cada cifra decimal. Existen varias versiones de este código:
-BCD natural: Sistema que codifica cifra a cifra del 0 al 9 con 4 bits y su valor binario sin más. La tabla de equivalencias entre el sistema decimal y el BCD natural es:
|
DECIMAL |
BCD NATURAL |
||
|
0 1 2 3 4 5 6 7 8 9 |
0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 |
El 13, por ejemplo, tedrá una codificación:
0001 0011
-
3
Mientras que en binario puro se representa como:
1011
Otros dos sistemas de codificación basados en el código BCD natural son:
-Decimal desempaquetado: En este sistema, un número se almacena con un byte por cada una de sus cifras. Cada byte lleva en su cuarteto de la izquierda de la última cifra representa el signo. Contenido 1100 para el “+“ y 1101 para el “-“ (C y D respectivamente en hexadecimal)
Por ejemplo:
1992 1111 0001 1111 1001 1111 1001 1100 0010
1 9 9 signo + 2
-1992 1111 0001 1111 1001 1111 1001 1100 0010
1 9 9 signo - 2
-Decimal empaquetado: En este sistema, se elimina el cuarteto de la izquierda del sistema anterior, en el que éste no contenía información salvo en la última cifra. En este caso cada cuarteto lleva una cifra en BCD, salvo el primero por la derecha que lleva el signo.
Por ejemplo:
1992 0000 0001 1001 1001 0010 1100
1 9 9 2 signo +
-1992 0000 0001 1001 1001 0010 1101
1 9 9 2 signo -
NÚMEROS
Cotidianamente, para representar los números utilizamos un sistema posicional de base 10: el sistema decimal. En este sistema los números son representados usando diez diferentes caracteres, llamados dígitos decimales, a saber, 0;1;2;3;4;5;6;7;8;9. La magnitud con la que un dado dígito a contribuye al valor del número depende de su posición en el número de manera tal que, si el dígito ocupa la posición n a la izquierda del punto decimal, el valor con que contribuye es a10n1 , mientras que si ocupa la posición n a la derecha del punto decimal, su contribución es a10n. Por ejemplo, la secuencia de dígitos 472:83 significa
472:83 = 4102 +7101 +2100 +8101 +3102
:
En general, la representación decimal
(1) s (anan1 a1a0:a1a2 )
corresponde al número
(1)s (an10n +an110n1 ++a1101 +a0100 +a1101 +a2102 +:::);
donde s depende del signo del número (s = 0 si el número es positivo y s = 1 si es negativo). De manera análoga se puede concebir otros sistemas posicionales con una base distinta de 10. En principio, cualquier número natural b 2 puede ser utilizado como base. Entonces, fijada una base, todo número real admite una representación posicional en la base b de la forma
(1)s (anb
n +an1b
n1 ++a1b
1 +a0b
0 +a1b
1 +a2b
2 +:::);
donde los coeficientes ai son los “dígitos” en el sistema con base b, esto es, enteros positivos tales que 0 ai b 1. Los coeficientes ai0 se consideran como los dígitos de la parte entera, en tanto que los ai<0, son los dígitos de la parte fraccionaria. Si, como en el caso decimal, utilizamos un punto para separar tales partes, el número es representado en la base b como
(1) s
(anan1 a1a0:a1a2 )b;
donde hemos utilizado el subíndice b para evitar cualquier ambigüedad con la base escogida. Una de las grandes ventajas de los sistemas posicionales es que se pueden dar reglas generales simples para las operaciones aritméticas2. Además tales reglas resultan más simples cuanto más pequeña es la base.
Esta observación nos lleva a considerar el sistema de base b = 2, o sistema binario, en donde sólo tenemos los dígitos 0 y 1. Pero existe otra razón. Una computadora, en su nivel más básico, sólo puede registrar si fluye o no electricidad por cierta parte de un circuito. Estos dos estados pueden representar entonces dos dígitos, convencionalmente, 1 cuando hay flujo de electricidad, 0 cuando no lo hay. Con una serie de circuitos apropiados una computadora puede entonces contar (y realizar operaciones aritméticas) en el sistema binario. El sistema binario consta, pues, sólo de los dígitos 0 y 1, llamados bits (del inglés binary digits). El 1 y el 0 en notación binaria tienen el mismo significado que en notación decimal 02 = 010; 12 = 110;
y las tablas de adición y multiplicación toman la forma
0+0 = 0; 0+1 = 1+0 = 1; 1+1 = 10;
00 = 0; 01 = 10 = 0; 11 = 1:
Otros números se representan con la notación posicional explicada anteriormente. Así, por ejemplo, 1101.01 es la representación binaria del número 13.25 del sistema decimal, esto es, (1101:01)2 = (13:25)10;
puesto que, 12
3 +12
2 +02
1 +12
0 +02
1 +12
2 = 13+0:25 = 13:25:
Además del sistema binario, otros dos sistemas posicionales resultan de interés en el ámbito computacional, a saber, el sistema con base b = 8, denominado sistema octal, y el sistema con base b = 16, denominado sistema hexadecimal. El sistema octal usa dígitos del 0 al 7, en tanto que el sistema hexadecimal usa los dígitos del 0 al 9 y las letras A, B, C, D, E, F3
. Por ejemplo,
(13:25)10 = (1101:01)2 = (15:2)8 = (D:4)16
La gran mayoría de las computadoras actuales (y efectivamente todas las computadoras personales, o PC) utilizan internamente el sistema binario (b = 2). Las calculadoras, por su parte, utilizan el sistema decimal (b = 10). Ahora bien, cualquiera sea la base b escogida, todo dispositivo de cálculo sólo puede almacenar un número finito de dígitos para representar un número. En particular, en una computadora sólo se puede disponer de un cierto número finito fijo N de posiciones de memoria para la representación de un número. El valor de N se conoce como longitud de palabra (en inglés, word length). Además, aún cuando en el sistema binario cualquier número puede representarse tan sólo con los dígitos 1 y 0, el signo y el punto, la representación
interna en la computadora no tiene la posibilidad de disponer de los símbolos signo y punto. De este modo una de tales posiciones debe ser reservada de algún modo para indicar el signo y cierta distinción debe hacerse para representar la parte entera y fraccionaria. Esto puede hacerse de distintas formas. En las siguientes secciones discutiremos, en primer lugar, la representación de punto fijo (utilizada para representar los números enteros) y, en segundo lugar, la representación de punto flotante (utilizada para representar los números reales).
CARACTERES
Son códigos utilizados por los ordenadores para guardar y transmitir información, así como para enviar órdenes entre dispositivos. En ellos podemos definir las siguientes características:
En estos códigos, en general, se representa cada carácter por medio de 8 bits, con lo cual, todo tipo de información puede ser utilizada internamente formando cadenas de bytes sucesivos que representan cadenas de caracteres.
Los primeros códigos utilizados fueron los de 6 bits que permitían la representación de 64 caracteres. Estos eran:
Más tarde se pasó a los 7 bits, entro los que podemos citar el código ASCII (American Estándar Code for Information Interchange). En la actualidad se utilizan exclusivamente códigos de 8 bits, entre los que podemos citar el código EBCDIC (Extended Binary Coded Decimal Interchange Code) y el ASCII extendido
-
-
Conjunto de caracteres:
-
Las 10 cifras del sistema decimal (0 al 9)
-
Las letras del alfabeto (mayúsculas y minúsculas)
-
Los signos de puntuación (, . : ; + * /).
-
Los caracteres de control (órdenes entre dispositivos)
-
Longitud de un código binario. Es el número de bits que utiliza para codificar un carácter.
-
Número máximo del conjunto de caracteres.
-
26 mayúsculas
-
10 numéricos
-
28 especiales
-
CÓDIGOS PARA CONTROL DE ERRORES
El código de control es un mecanismo de detección de errores utilizado para verificar la corrección de un dato, generalmente en soporte informático. Los dígitos de control se usan principalmente para detectar errores en el tecleo o transmisión de los datos.
Generalmente consisten en uno o más caracteres numéricos o alfabéticos añadidos al dato original y calculados a partir de éste mediante un determinado algoritmo. Algunos de los ejemplos de uso frecuentes son los números de identificación personal, códigos de barras, tarjetas de crédito y códigos bancarios.
Denominación
No existe unanimidad en la denominación de esta técnica en el mundo hispanoparlante. La traducción directa del inglés check digit sería dígito de chequeo, de verificación o de control. Estas denominaciones solamente son aplicables cuando se trata, efectivamente, de uno o varios dígitos y no de otros caracteres. Más correctas son las variantes carácter de chequeo, de verificación ode control, aunque ésta última tiene otro significado específico en el contexto de la informática. También son aplicables código de control (la forma más usada de entre las correctas), de chequeoo de verificación, aunque esta última expresión se refiere casi siempre a técnicas para filtrar el acceso a páginas web, como los captcha.
Utilización
Es utilizado normalmente en representaciones numéricas que exijan integridad, como por ejemplo:
-
Documentos de identificación: Algunos documentos de identificación como la cédula de identidad o el DNI dependiendo del país.
-
Códigos de pagos: Número de factura, número de identificación tributaria, etc.
-
Códigos en general: Cuenta bancaria, cuenta corriente, número de matrícula, código de barras, ISBN, etc.
Cálculo del dígito verificador
El método de cálculo de esos dígitos varía conforme el caso. Sin embargo, muchos de ellos se basan en dos rutinas tradicionales: Módulo 11 y Módulo 10.
ACCESO A MEMORIA
El acceso directo a memoria (DMA, del inglés direct memory access) permite a cierto tipo de componentes de una computadora acceder a la memoria del sistema para leer o escribir independientemente de la unidad central de procesamiento (CPU) principal. Muchos sistemas hardware utilizan DMA, incluyendo controladores de unidades de disco, tarjetas gráficas y tarjetas de sonido. DMA es una característica esencial en todos los ordenadores modernos, ya que permite a dispositivos de diferentes velocidades comunicarse sin someter a la CPU a una carga masiva de interrupciones.
Una transferencia DMA consiste principalmente en copiar un bloque de memoria de un dispositivo a otro. En lugar de que la CPU inicie la transferencia, la transferencia se lleva a cabo por el controlador DMA. Un ejemplo típico es mover un bloque de memoria desde una memoria externa a una interna más rápida. Tal operación no ocupa al procesador y, por ende, éste puede efectuar otras tareas. Las transferencias DMA son esenciales para aumentar el rendimiento de aplicaciones que requieran muchos recursos.
Cabe destacar que aunque no se necesite a la CPU para la transacción de datos, sí se necesita el bus del sistema (tanto bus de datos como bus de direcciones), por lo que existen diferentes estrategias para regular su uso, permitiendo así que no quede totalmente acaparado por el controlador DMA.
El acceso directo a memoria es simplemente eso, un acceso a memoria que se crea al particionar la memoria en bloques del mismo tamaño.
PROCESO DE LECTURA
Proceso de lectura de una palabra (64 bits) de la memoria. El módulo cuenta con 8 chips de 8 matrices o bancos cada uno. Para llenar el Buffer de Entrada/Salida donde se almacenan los datos antes de ser enviados a bus de datos, se tienen que hacer ocho lecturas de celdas contiguas.
En este ejemplo leen las celdas ubicadas donde se cruzan la fila 4 con la columna 420 a 427. Luego de cada una de las lecturas se envían los datos a un espacio de almacenamiento temporal llamado Buffer de Entrada/Salida, donde se mantienen temporalmente los bits leídos hasta juntarse 64 de ellos y poder ser enviados por bus de datos.

PROCESO DE ESCRITURA
Para efectuar el proceso de escritura en la memoria RAM hacemos lo siguiente:
En primer lugar alimentamos el integrado .Depués conectamos a masa las patillas 4,3,2,1,17 y 16.A continuación conectamos las patillas 14 y 13 y las llevamos a un interruptorPor medio de estas patillas introducimos los datos en la memoria RAM.
Hacemos lo mismo con las patillas 12 y 11.
A continuación llevamos a cuatro interruptores las patillas 5 ,6,7 y 15 para poder direccionar el contenido de la RAM.Depués la patilla 8 la ponemos a 1 y la patilla 10 a 0.
CARACTERÍSTICAS
1.- Son volátiles (trabajan con voltaje)
2.- Es la memoria desde donde el procesador recibe las instrucciones y guarda los resultados.
3.- Es el área de trabajo para la mayor parte del software de un computador.
4.- Son memorias de acceso aleatorio.
5.- No son medios de almacenamiento, las memorias RAM le dan velocidad a una computadora para ejecutar programas más rapidamente, si es que se la amplía (ejemplo: tengo una memoria RAM de 1 GB y la cambio por una de 2 GB, mi computadora funcionará mas rápido)
CAPACIDAD
Memorias de mayor capacidad son el resultado de la rápida evolución en tecnología de materiales semiconductores. Los primeros programas de ajedrez funcionaban en máquinas que utilizaban memorias de base magnética. A inicios de 1970 aparecen las memorias realizadas por semiconductores, como las utilizadas en la serie de computadoras IBM 370.
La velocidad de los computadores se incrementó, multiplicada por 100.000 aproximadamente y la capacidad de memoria creció en una proporción similar. Este hecho es particularmente importante para los programas que utilizan tablas de transposición: a medida que aumenta la velocidad de la computadora se necesitan memorias de capacidad proporcionalmente mayor para mantener la cantidad extra de posiciones que el programa está buscando.
Se espera que la capacidad de procesadores siga aumentando en los próximos años; no es un abuso pensar que la capacidad de memoria continuará creciendo de manera impresionante. Memorias de mayor capacidad podrán ser utilizadas por programas con tablas de Hash de mayor envergadura, las cuales mantendrán la información en forma permanente.
-
Minicomputadoras: se caracterizan por tener una configuración básica regular que puede estar compuesta por un monitor, unidades de disquete, disco, impresora, etc. Su capacidad de memoria varía de 16 a 256 kbytes.
-
Macrocomputadoras: son aquellas que dentro de su configuración básica contienen unidades que proveen de capacidad masiva de información, terminales (monitores), etc. Su capacidad de memoria varía desde 256 a 512 kbytes, también puede tener varios megabytes o hasta gigabytes según las necesidades de la empresa.
-
Microcomputadores y computadoras personales: con el avance de la microelectrónica en la década de los 70 resultaba posible incluir todos los componente del procesador central de una computadora en un solo circuito integrado llamado microprocesador. Ésta fue la base de creación de unas computadoras a las que se les llamó microcomputadoras. El origen de las microcomputadoras tuvo lugar en los Estados Unidos a partir de la comercialización de los primeros microprocesadores (INTEL 8008, 8080). En la década de los 80 comenzó la verdadera explosión masiva, de los ordenadores personales (Personal Computer PC) de IBM. Esta máquina, basada en el microprocesador INTEL 8008, tenía características interesantes que hacían más amplio su campo de operaciones, sobre todo porque su nuevo sistema operativo estandarizado (MS-DOS, Microsoft Disk Operating Sistem) y una mejor resolución óptica, la hacían más atractiva y fácil de usar. El ordenador personal ha pasado por varias transformaciones y mejoras que se conocen como XT(Tecnología Extendida), AT(Tecnología Avanzada) y PS/2...
TIEMPO DE ACCESO
-
Acceso aleatorio significa que se puede acceder a cualquier localización de la memoria en cualquier momento en el mismo intervalo de tiempo, normalmente pequeño.
-
Acceso secuencial significa que acceder a una unidad de información tomará un intervalo de tiempo variable, dependiendo de la unidad de información que fue leída anteriormente. El dispositivo puede necesitar buscar (posicionar correctamente el cabezal de lectura/escritura de un disco), o dar vueltas (esperando a que la posición adecuada aparezca debajo del cabezal de lectura/escritura en un medio que gira continuamente).
VOLATILIDAD
-
La memoria volátil requiere energía constante para mantener la información almacenada. La memoria volátil se suele usar sólo en memorias primarias. La memoria RAM es una memoria volátil, ya que pierde información en la falta de energía eléctrica.
-
La memoria no volátil retendrá la información almacenada incluso si no recibe corriente eléctrica constantemente, como es el caso de la memoria ROM. Se usa para almacenamientos a largo plazo y, por tanto, se usa en memorias secundarias, terciarias y fuera de línea.
-
La memoria dinámica es una memoria volátil que además requiere que periódicamente se refresque la información almacenada, o leída y reescrita sin modificaciones.
COSTO
SDR: Capacidad máxima por memoria: 512 MB.
Precios:
512 MB $* 105.00 = U$S 30
128 MB $* 45.00 = U$S 12.50
256 MB $* 60.00 = U$S 17
DDR: Capacidad máxima por memoria: 1GB
Precios:
512 MB $* 90.00 = U$S 25
1 GB $* 165.00 = U$S 45
DDR2: Capacidad máxima por memoria: 2GB
Precios:
512 MB $* 60.00 = U$S 17
1 GB $* 70.00 = U$S 16.50
2 GB $* 110 = U$S 30.50
DDR3: (La lectura y escritura de datos es mucho mas superior que la DDR2) Capacidad máxima por memoria: 2GB
Precios:
1GB $* 200.00 = U$S
2GB $* 305.00 = U$S
DIMM: (Velocidad de lectura y escritura mayor qe la DDR2 y menor qe la DDR3) Capacidad máxima por memoria: 2GB
Precios:
512 MB $* 60.00 = U$S 17
1 GB $* 75.00 = U$S 21
2 GB $* 110.00 = U$S 30.50
CLASIFICACIÓN
En términos generales, existen dos grandes categorías de memoria de acceso aleatorio:
· Las memorias DRAM (Módulo de Acceso Aleatorio Dinámico), las cuales son menos costosas. Se utilizan principalmente para la memoria principal del ordenador
· Las memorias SRAM (Módulo de Acceso Aleatorio Estático), rápidas pero relativamente costosas. Las memorias SRAM se utilizan en particular en la memoria caché del procesador
Formatos de módulos Ram
Existen diferentes tipos de memoria de acceso aleatorio. Estas se presentan en forma de módulos de memoria que pueden conectarse a la placa madre.
Las primeras memorias fueron chips denominados DIP (Paquete en Línea Doble). Hoy en día, las memorias por lo general se suministran en forma de módulos, es decir, tarjetas que se colocan en conectores designados para tal fin. En términos generales, existen tres tipos de módulos RAM:
-
Módulos en formato SIMM (Módulo de Memoria en Línea Simple): se trata de placas de circuito impresas, con uno de sus lados equipado con chips de memoria. Existen dos tipos de módulos SIMM, según el número de conectores.
-
Módulos SIMM con 30 conectores (de 89x13mm) son memorias de 8 bits que se instalaban en los PC de primera generación (286, 386).
-
Módulos SIMM con 72 conectores (sus dimensiones son 108x25mm) son memorias capaces de almacenar 32 bits de información en forma simultánea. Estas memorias se encuentran en los PC que van desde el 386DX hasta los primeros Pentiums. En el caso de estos últimos, el procesador funciona con un bus de información de 64 bits, razón por la cual, estos ordenadores necesitan estar equipados con dos módulos SIMM. Los módulos de 30 clavijas no pueden instalarse en posiciones de 72 conectores, ya que la muesca (ubicada en la parte central de los conectores) imposibilitaría la conexión.
Módulos en formato DIMM (Módulo de Memoria en Línea Doble), son memorias de 64 bits, lo cual explica por qué no necesitan emparejamiento. Los módulos DIMM poseen chips de memoria en ambos lados de la placa de circuito impresa, y poseen a la vez, 84 conectores de cada lado, lo cual suma un total de 168 clavijas. Además de ser de mayores dimensiones que los módulos SIMM (130x25mm), estos módulos poseen una segunda muesca que evita confusiones.
Cabe observar que los conectores DIMM han sido mejorados para facilitar su inserción, gracias a las palancas ubicadas a ambos lados de cada conector.
-
Módulos en formato
-
SO DIMM
-
(DIMM de contorno pequeño), diseñados para ordenadores portátiles. Los módulos SO DIMM sólo cuentan con 144 clavijas en el caso de las memorias de 64 bits, y con 77 clavijas en el caso de las memorias de 32 bits.
-
-
Los módulos en formato RIMM:
-
(Módulo de Memoria en Línea Rambus, también conocido como RD-RAM o DRD-RAM) son memorias de 64 bits desarrolladas por la empresa Rambus. Poseen 184 clavijas. Dichos módulos poseen dos muescas de posición, con el fin de evitar el riesgo de confusión con módulos previos.
-
Dada la alta velocidad de transferencia de que disponen, los módulos RIMM poseen una película térmica cuyo rol es el mejorar la transferencia de calor.
-
Al igual que con los módulos DIMM, también existen módulos más pequeños, conocidos como SO RIMM
(RIMM de contorno pequeño), diseñados para ordenadores portátiles. Los módulos SO RIMM poseen sólo 160 clavijas.
DRAM PM
La DRAM (RAM Dinámica) es el tipo de memoria más común en estos tiempos. Se trata de una memoria cuyos transistores se disponen en forma de matriz, en forma de filas y columnas. Un transistor, acoplado con un capacitador, proporciona información en forma de bits. Dado que un octeto contiene 8 bits, un módulo de memoria DRAM de 256 Mo contendrá por lo tanto 256 * 2^10 * 2^10 = 256 * 1024 * 1024 = 268.435.456 octetos = 268.435.456 * 8 = 2.147.483.648 bits = 2.147.483.648 transistores. De esta manera, un módulo de 256 Mo posee una capacidad de 268.435.456 octetos, o 268 Mo. Los tiempos de acceso de estas memorias son de 60 ns.
Además, el acceso a la memoria en general se relaciona con la información almacenada consecutivamente en la memoria. De esta manera, el modo de ráfaga permite el acceso a las tres partes de información que siguen a la primera parte, sin tiempo de latencia adicional. De este modo, el tiempo necesario para acceder a la primera parte de la información es igual al tiempo del ciclo más el tiempo de latencia, mientras que el tiempo necesario para acceder a las otras tres partes de la información sólo es igual al tiempo de ciclo; los cuatro tiempos de acceso se expresan, entonces, en la forma X-Y-Y-Y. Por ejemplo, 5-3-3-3 indica que la memoria necesita 5 ciclos del reloj para acceder a la primera parte de la información, y 3 para acceder a las subsiguientes.
DRAM FPM
Para acelerar el acceso a la DRAM, existe una técnica, conocida como paginación, que permite acceder a la información ubicada en una misma columna, modificando únicamente la dirección en la fila, y evitando de esta manera, la repetición del número de columna entre lecturas por fila. Este proceso se conoce como DRAM FPM (Memoria en Modo Paginado). El FPM alcanza tiempos de acceso de unos 70 u 80 nanosegundos, en el caso de frecuencias de funcionamiento de entre 25 y 33 Mhz.
DRAM EDO
La DRAM EDO se introdujo en 1995. La técnica utilizada en este tipo de memoria implica direccionar la columna siguiente mientras paralelamente se está leyendo la información de una columna anterior. De esta manera, se crea un acceso superpuesto que permite ahorrar tiempo en cada ciclo. El tiempo de acceso de la memoria EDO es de 50 a 60 nanosegundos, en el caso de una frecuencia de funcionamiento de entre 33 y 66 Mhz.
De modo que la RAM EDO, cuando se utiliza en modo ráfaga, alcanza ciclos 5-2-2-2, lo cual representa una ganancia de 4 ciclos al acceder a 4 partes de información. Dado que la memoria EDO no funcionaba con frecuencias mayores a 66 Mhz, se suspendió su uso en favor de la SDRAM.
SDRAM
La SDRAM (DRAM Sincrónica), introducida en 1997, permite la lectura de la información sincronizada con el bus de la placa madre, a diferencia de lo que ocurre con las memorias EDO y FPM (conocidas comoasincrónicas), las cuales poseen reloj propio. La SDRAM elimina de esta manera, los tiempos de espera ocasionados por la sincronización con la placa madre. Gracias a esto se logra un ciclo de modo ráfaga de 5-1-1-1, con una ganancia de 3 ciclos en comparación con la RAM EDO. La SDRAM puede, entonces, funcionar con una frecuencia mayor a 150 MHz, logrando tiempos de acceso de unos 10 ns.
DR-SDRAM (Rambus DRAM)
La DR-SDRAM (DRAM Directa de Rambus), es un tipo de memoria que permite la transferencia de datos a un bus de 16 bits y a una frecuencia de 800 Mhs, lo que proporciona un ancho de banda de 1,6 GB/s. Al igual que la SDRAM, este tipo de memoria está sincronizada con el reloj del bus, a fin de mejorar el intercambio de información. Sin embargo, la memoria RAMBUS es un producto de tecnología patentada, lo que implica que cualquier empresa que desee producir módulos RAM que utilicen esta tecnología deberá abonar regalías, tanto a RAMBUS como a Intel.
DDR-SDRAM
La DDR-SDRAM (SDRAM de Tasa Doble de Transferencia de Datos) es una memoria basada en la tecnología SDRAM, que permite duplicar la tasa de transferencia alcanzada por ésta utilizando la misma frecuencia.
La información se lee o ingresa en la memoria al igual que un reloj. Las memorias DRAM estándares utilizan un método conocido como SDR (Tasa Simple de Transferencia de Datos), que implica la lectura o escritura de información en cada borde de entrada.
La DDR permite duplicar la frecuencia de lectura/escritura con un reloj a la misma frecuencia, enviando información a cada borde de entrada y a cada borde posterior.
Las memorias DDR por lo general poseen una marca, tal como PCXXXX, en la que "XXXX" representa la velocidad en MB/s.
DDR2-SDRAM
Las memorias DDR2 (o DDR-II) alcanzan velocidades dos veces superiores a las memorias DDR con la misma frecuencia externa.
El acrónimo QDR (Tasa Cuádruple de Transferencia de Datos o con Quad-pump) designa el método de lectura y escritura utilizado. De hecho, la memoria DDR2 utiliza dos canales separados para los procesos de lectura y escritura, con lo cual es capaz de enviar o recibir el doble de información que la DDR.
La DDR2 también posee más conectores que la DDR clásica (la DDR2 tiene 240, en comparación con los 184 de la DDR).
DDR3-SDRAM
DDR3 es un tipo de memoria RAM. Forma parte de la familia SDRAM de tecnologías de memoria de acceso aleatorio, que es una de las muchas implementaciones de la SDRAM.
El principal beneficio de instalar DDR3 es la habilidad de poder hacer transferencias de datos más rápido,y con esto nos permite obtener velocidades de transferencia y velocidades de bus más altas que las versiones DDR2 anteriores. Sin embargo, no hay una reducción en lalatencia, la cual es proporcionalmente más alta. Además la DDR3 permite usar integrados de 512 MB a 8 GB, siendo posible fabricar módulos de hasta 16 GiB. También proporciona significativas mejoras en el rendimiento en niveles de bajo voltaje, lo que lleva consigo una disminución del gasto global de consumo.
Se prevé que la tecnología DDR3 puede ser dos veces más rápida que la DDR2 y el alto ancho de banda que promete ofrecer DDR3 es la mejor opción para la combinación de un sistema con procesadores dual-core, quad-core y hexaCore (2, 4 y 6 núcleos por microprocesador). Las tensiones más bajas del DDR3 (1,5 V frente 1,8 V de DDR2) ofrecen una solución térmica y energética más eficientes.
ROM
Conocida también como ROM (acrónimo en inglés de read-only memory), es un medio de almacenamiento utilizado en ordenadores y dispositivos electrónicos, que permite sólo la lectura de la información y no su escritura, independientemente de la presencia o no de una fuente de energía.
Los datos almacenados en la ROM no se pueden modificar, o al menos no de manera rápida o fácil. Se utiliza principalmente en su sentido más estricto, se refiere sólo a máscara ROM -en inglés, MROM- (el más antiguo tipo de estado sólido ROM), que se fabrica con los datos almacenados de forma permanente y, por lo tanto, su contenido no puede ser modificado de ninguna forma. Sin embargo, las ROM más modernas, como EPROM y Flash EEPROM, efectivamente se pueden borrar y volver a programar varias veces, aun siendo descritos como "memoria de sólo lectura" (ROM). La razón de que se las continúe llamando así es que el proceso de reprogramación en general es poco frecuente, relativamente lento y, a menudo, no se permite la escritura en lugares aleatorios de la memoria. A pesar de la simplicidad de la ROM, los dispositivos reprogramables son más flexibles y económicos, por lo cual las antiguas máscaras ROM no se suelen encontrar en hardware producido a partir de 2007.
RAM
La memoria de acceso aleatorio (en inglés: random-access memory) se utiliza como memoria de trabajo para el sistema operativo, los programas y la mayoría del software. Es allí donde se cargan todas las instrucciones que ejecutan el procesador y otras unidades de cómputo. Se denominan «de acceso aleatorio» porque se puede leer o escribir en una posición de memoria con un tiempo de espera igual para cualquier posición, no siendo necesario seguir un orden para acceder a la información de la manera más rápida posible. Durante el encendido del computador, la rutina POST verifica que los módulos de memoria RAM estén conectados de manera correcta. En el caso que no existan o no se detecten los módulos, la mayoría de tarjetas madres emiten una serie de pitidos que indican la ausencia de memoria principal. Terminado ese proceso, la memoria BIOS puede realizar un test básico sobre la memoria RAM indicando fallos mayores en la misma.
PROM
PROM es el acrónimo de Programmable Read-Only Memory (ROM programable). Es una memoria digital donde el valor de cada bit depende del estado de un fusible (o antifusible), que puede ser quemado una sola vez. Por esto la memoria puede ser programada (pueden ser escritos los datos) una sola vez a través de un dispositivo especial, un programador PROM. Estas memorias son utilizadas para grabar datos permanentes en cantidades menores a las ROMs, o cuando los datos deben cambiar en muchos o todos los casos.
Pequeñas PROM han venido utilizándose como generadores de funciones, normalmente en conjunción con un multiplexor. A veces se preferían a las ROM porque son bipolares, habitulamente Schottky, consiguiendo mayores velocidades.
EPROM
EPROM son las siglas de Erasable Programmable Read-Only Memory (ROM programable borrable). Es un tipo de chip de memoria ROM no volátilinventado por el ingeniero Dov Frohman. Está formada por celdas de FAMOS (Floating Gate Avalanche-Injection Metal-Oxide Semiconductor) o "transistores de puerta flotante", cada uno de los cuales viene de fábrica sin carga, por lo que son leídos como 1 (por eso, una EPROM sin grabar se lee como FF en todas sus celdas).
Características
Las memorias EPROM se programan mediante un dispositivo electrónico que proporciona voltajes superiores a los normalmente utilizados en los circuitos electrónicos. Las celdas que reciben carga se leen entonces como un 0.
Una vez programada, una EPROM se puede borrar solamente mediante exposición a una fuerte luz ultravioleta. Esto es debido a que los fotones de la luz excitan a los electrones de las celdas provocando que se descarguen. Las EPROM se reconocen fácilmente por una ventana transparente en la parte alta del encapsulado, a través de la cual se puede ver el chip de silicio y que admite la luz ultravioleta durante el borrado.
Como el cuarzo de la ventana es caro de fabricar, se introdujeron los chips OTP (One-Time Programmable, programables una sola vez). La única diferencia con la EPROM es la ausencia de la ventana de cuarzo, por lo que no puede ser borrada. Las versiones OTP se fabrican para sustituir tanto a las EPROM normales como a las EPROM incluidas en algunos microcontroladores. Estas últimas fueron siendo sustituidas progresivamente por EEPROMs(para fabricación de pequeñas cantidades donde el coste no es lo importante) y por memoria flash (en las de mayor utilización).
Una EPROM programada retiene sus datos durante diez o veinte años, y se puede leer un número ilimitado de veces. Para evitar el borrado accidental por la luz del sol, la ventana de borrado debe permanecer cubierta. Las antiguas BIOS de los ordenadores personales eran frecuentemente EPROM y la ventana de borrado estaba habitualmente cubierta por una etiqueta que contenía el nombre del productor de la BIOS, su revisión y una advertencia decopyright.
ESTRUCTURA FÍSICA
NÚCLEOS DE FERRITA
Los primeros ordenadores estaban dotados de memorias que almacenaban sus datos en forma de campo magnético en núcleos de ferrita, los cuales estaban ensamblados en conjuntos de núcleos de memoria.
El polvo de ferrita se usa también en la fabricación de cintas para grabación; en este caso, el material es trióxido de hierro. Otra utilización común de los núcleos de ferrita es su uso en multitud de cables electrónicos para minimizar las interferencias electromagnéticas (EMI). Se disponen en alojamientos deplástico que agarran el cable mediante un sistema de cierre. Al pasar el cable por el interior del núcleo aumenta la impedancia de la señal sin atenuar lasfrecuencias más bajas. A mayor número de vueltas dentro del núcleo mayor aumento, por eso algunos fabricantes presentan cables con bucles en los núcleos de ferrita.
Este polvo de ferrita es utilizado también como tóner magnético de impresoras láser, pigmento de algunas clases de pintura, polvo de inspección magnético (usado en soldadura), tinta magnética para imprimir cheques y códigos de barras y, a su vez, con dicho polvo y la adición de un fluido portador (agua, aceite vegetal o mineral o de coche) y un surfactante o tensoactivo (ácido oleico, ácido cítrico, lecitina de soja) es posible fabricar ferrofluido casero.
INTEGRADAS
Una placa madre integrada, es aquella placa madre que viene equipada con todos los elementos y chips que le permiten controlar los periféricos conectados a la computadora (video, sonido, red, módem, etc), sin necesidad de tener que instalar otra tarjeta. Es decir, todos los chips controladores vienen integrados en una sola placa madre, lo que nos permitirá ahorrar dinero y evitar un sobrecalentamiento del PC.
Por supuesto, que el contar con una sola placa madre no nos limita si deseamos adicionar tarjetas o placas controladoras específicas, como por ejemplo, una placa de video, de sonido o de red. Actualmente, la mayoría de las placas madres que existen en el mercado son integradas, ya que son especialmente diseñadas para aprovechar al máximo la capacidad de la placa en equipos estándar, es decir, aquellos que no requieran de condiciones específicas de audio, video y redes, como por ejemplo, un servidor, un PC para trabajo de edición de video y audio, o un PC dedicado a ejecutar juegos de última generación.
Ventajas y desventajas de tener una placa madre integrada
Existen varias ventajas y desventajas de tener este tipo de placa madre, aunque todas estas son subjetivas, ya que el que tiene la última palabra siempre es el usuario final. Sin embargo, siempre hay parámetros generales estándar para el uso de estas placas madre que influyen mucho en optar por una de estas placas o no. A continuación, algunos de estos puntos ventajosos y desventajosos:
Ventajas:
-
Bajo costo.
-
Reducción del calentamiento interno del CPU.
-
La comodidad de tener todos los chips controladores en una sola placa.
-
Ahorro de espacio dentro del case.
-
Buena salida de audio, por lo general es bastante buena si no requerimos de audio profesional.
Desventajas:
-
Bajo rendimiento del video integrado, ya que estos controladores de video están diseñados para trabajos con bajo desempeño visual.
-
Mayor uso de recursos. Por lo general las placas integradas comparten lamemoria RAM, por lo que es necesario incrementarla para obtener un mejor desempeño.
-
Si deseamos realizar ediciones profesionales de video y audio en el PC, tendremos que adquirir tarjetas de video y sonido adicionales.
BURBUJAS MAGNÉTICAS
La memoria de burbuja (Bubble memory) es un tipo de memoria para almacenamiento no volátil que utiliza una película de material magnético de pequeño espesor que contiene pequeñas zonas magnetizadas conocidas como burbujas , que almacenan un bit de datos cada una.
A diferencia de lo que ocurre con la memoria de sólo lectura (ROM), se puede escribir en la memoria de burbujas. También a diferencia de la memoria de acceso aleatorio (RAM), los datos almacenados en las burbujas de memoria permanecerán allí hasta que se modifiquen, incluso cuando se apaga el equipo. Por tanto, la memoria de burbuja se ha utilizado en entornos en los que un equipo debe tener la capacidad de recuperarse de una falta de energía eléctrica, con una pérdida mínima de datos. El uso y la demanda de memorias de burbuja ha desaparecido con el advenimiento de la memoria flash, que es más barata y de más fácil producción.
La memoria de burbuja surgió a principios de 1970, como una tecnología prometedora, pero fue un fracaso comercial debido a la rápida caída de los precios de discos duros (HD) a principios de 1980.
OTRAS (FOTODIGÍTALES, RAYO LÁSER, BIOLÓGICAS, ETC.)
Existen diversas soluciones para el almacenamiento de datos, cada una de ellas diseñada para diferentes propósitos y cantidades. Estas soluciones incluyen medios grabables, discos duros externos y respaldos en línea. Sin embargo, la fiabilidad de una solución de almacenamiento de fotos digitales depende de su calidad, así que ten en cuenta que podrías necesitar más que una o dos soluciones de almacenamiento de fotos para respaldar adecuadamente tu biblioteca de imágenes digitales.
Almacenamiento de informacion en medios grabables
Los medios grabables como los discos CD-R, CD-RW, DVD-R y DVD-RW almacenarán desde cientos de megabytes de fotos digitales hasta varios gigabytes. Graba tus fotos en una de estas opciones de almacenamiento y guárdalas en un lugar seguro. Puedes acceder fácilmente a las imágenes si necesitas realizar copias o reemplazar archivos en tu disco duro. Lo único que necesitas además del medio grabable una unidad de CD/DVD con capacidad para grabar discos.
Unidades flash y discos SD
Una de las formas más rápidas para almacenar tus datos es una memoria USB o un disco SD. Esto sólo califica como un respaldo si guardas el dispositivo una vez que hayas copiado la información y no la usas para nada más. Estos dispositivos también pueden ser usados para transportar fotos digitales de una computadora a otra con facilidad o mientras estás de viaje. Los discos SD también cuentan con un mecanismo de bloqueo en el costado para evitar borrar información de forma accidental cuando están conectados en una computadora. Sin embargo, la información se puede dañar en estos tipos de unidades de almacenamiento. FreeComputerConsultant.com recomienda usar un software de recuperación de fotos para discos SD y medios portátiles similares si no puedes recuperar la información después de copiarla en estos dispositivos.
Unidades de almacenamiento en red
Según 1nas.com, las unidades de almacenamiento en red ofrecen una de las formas más confiable para respaldar tu información, o en este caso, tus fotos digitales. Estos dispositivos no son sólo un disco duro externo, ya que te brindan la posibilidad de acceder a la información a través de una red, en lugar de confiar en el disco duro de tu computadora, el cual tiene una alta probabilidad de fallar en algún momento. Debido a que muchas unidades de almacenamiento en red incluyen variosterabytes de espacio disponible, probablemente no necesitas más de uno para almacenar tus fotos.
Almacenamiento en línea
Existen dos tipos diferentes de soluciones de almacenamiento en línea para fotos. El primer tipo requiere que cargues todas tus fotos, ya sea de forma individual o en masa, a un dominio en línea. La segunda opción es descargar un programa que respalde constantemente tu información enviándola a un centro de almacenamiento en línea directamente desde tu computadora. Aunque los archivos todavía son transferidos a través de una carga, no tienes que detenerte por completo y facilita el proceso con el programa de respaldo en línea. Resulta prudente utilizar un respaldo en línea, ya que puedes acceder a tus datos desde otra computadora si la tuya presenta problemas, pero si no tienes acceso a una computadora durante un tiempo, no podrás recuperar tus fotos digitales. En este caso, tener tus fotos respaldadas de forma local al menos te permitirá mantener las fotos bajo tu posesión hasta que la computadora vuelva a funcionar.
UNIDAD DE CONTROL
La unidad de control (UC) es uno de los tres bloques funcionales principales en los que se divide una unidad central de procesamiento (CPU). Los otros dos bloques son la unidad de proceso y el bus de entrada/salida.
Su función es buscar las instrucciones en la memoria principal, decodificarlas (interpretación) y ejecutarlas, empleando para ello la unidad de proceso.
Existen dos tipos de unidades de control, las cableadas, usadas generalmente en máquinas sencillas, y las microprogramadas, propias de máquinas más complejas. En el primer caso, los componentes principales son el circuito de lógica secuencial, el de control de estado, el de lógica combinacional y el de emisión de reconocimiento de señales de control. En el segundo caso, la microprogramación de la unidad de control se encuentra almacenada en una micromemoria, a la cual se accede de manera secuencial para posteriormente ir ejecutando cada una de las microinstrucciones. Estructura del computador: Unidad aritmético-lógica (UAL o ALU por su nombre en inglés, Arithmetic Logic Unit): aquí se llevan a cabo las operaciones aritméticas y lógicas.
Por otra parte esta la unidad de control, que fue históricamente definida como una parte distinta del modelo de referencia de 1946 de la Arquitectura de von Neumann. En diseños modernos de computadores, la unidad de control es típicamente una parte interna del CPU y fue conocida primeramente como arquitectura Eckert-Mauchly. Memoria: que almacena datos y programas. Dispositivos de entrada y salida: alimentan la memoria con datos e instrucciones y entregan los resultados del cómputo almacenados en memori. Buses: proporcionan un medio para transportar los datos e instrucciones entre las distintos y pequeños que la memoria principal (los registros), constituyen la unidad central de procesamiento (UCP o CPU por su nombre en inglés: Central Processing Unit)
SECUENCIA LÓGICA DE FUNCIONES
La función principal de la unidad de control de la UCP es dirigir la secuencia de pasos de modo que la computadora lleve a cabo un ciclo completo de ejecución de una instrucción, y hacer esto con todas las instrucciones de que conste el programa. Los pasos para ejecutar una instrucción cualquiera son los siguientes:
-
Ir a la memoria y extraer el código de la siguiente instrucción (que estará en la siguiente celda de memoria por leer). Este paso se llama ciclo de fetch en la literatura computacional (to fetch significa traer, ir por).
-
Decodificar la instrucción recién leída (determinar de qué instrucción se trata).
-
Ejecutar la instrucción.
-
Prepararse para leer la siguiente casilla de memoria (que contendrá la siguiente instrucción), y volver al paso 1 para continuar.
La unidad de control ejecutará varias veces este ciclo de cuatro “instrucciones alambradas” a una enorme velocidad. Se llama así a estas instrucciones porque no residen en memoria, ni fueron escritas por ningún programador, sino que la maquina las ejecuta directamente por medios electrónicos, y lo hará mientras esté funcionando (mientras este encendida) en una computadora es a razón de cientos de miles (o incluso millones) de veces por segundo.


LOCALIZACIÓN Y EXTRACCIÓN DEL EX DE LA INSTRUCCIÓN
- La ejecución de una instrucción se descompone en pasos llamados operaciones elementales.
- Comienzan con un dato que se encuentra en algún elemento de estado (capaz de almacenar información).
- Terminan con el resultado de la operación en algún elemento de estado.
- Distintas operaciones elementales se pueden ejecutar en el mismo ciclo de reloj (si no se estorban).
TRANSFERENCIAS DE MEMORIA PRINCIPAL A LA UNIDAD DE CONTROL
La función principal de estos dispositivos es adaptar la información procesada por la unidad central de proceso, canalizando las transferencias de información entre la computadora y los dispositivos periféricos exteriores.
Con las tarjetas controladoras de entrada y salida de datos se consigue:
-
Independencia funcional entre la unidad central de proceso y los periféricos asociados a ella. Las tarjetas controladoras evitan la lentitud de los procesos debido a la diferencia de velocidad entre la CPU y los periféricos.
-
Adaptación de diversos tipos de periféricos al sistema informático, independientemente de que la operatividad entre ellos y la computadora no sea compatible.
-
Pueden servir de traductoras entre el modo digital de la computadora y el analógico del de otros medios por los que se pueden establecer enlaces entre sistemas informáticos.
DEFINICIONES DE LA INSTRUCCIÓN
Un ciclo de instrucción (también llamado ciclo de fetch-and-execute o ciclo de fetch-decode-execute en inglés) es el período que tarda la unidad central de proceso (CPU) en ejecutar una instrucción de lenguaje máquina.
Comprende una secuencia de acciones determinada que debe llevar a cabo la CPU para ejecutar cada instrucción en un programa. Cada instrucción del juego de instrucciones de una CPU puede requerir diferente número de ciclos de instrucción para su ejecución. Un ciclo de instrucción está formado por uno o más ciclos máquina.
Para que cualquier sistema de proceso de datos basado en microprocesador (por ejemplo un ordenador) o microcontrolador (por ejemplo un reproductor de MP3) realice una tarea (programa) primero debe buscar cada instrucción en la memoria principal y luego ejecutarla.
EJECUCIÓN
Controla y coordina el funcionamiento de las partes que integran una computadora, determina que operaciones se deben realizar y en que orden; asimismo sincroniza todo el proceso de la computadora, dependiendo de la interpretación de las instrucciones que integran los programas, genera el conjunto de ordenes elementales necesarias para que se realice los procesos necesarios.
Los pasos que sigue la unidad de control para ejecutar sus operaciones se pueden resumir como sigue, se extrae de la memoria principal la instrucción a ejecutar, esa información es almacenada en el contador de instrucciones, la información que se almacena es la próxima instrucción a ejecutar en el registro de instrucción propiamente dicha,. una vez conocido el código de la operación a ejecutar la unidad de control ya sabe que circuitos de la UAL deben intervenir, pueden establecerse las conexiones eléctricas necesarias a través del secuenciador, extrae de la memoria principal los datos necesarios para ejecutar la instrucción en proceso, ordena a la AUL que efectúe las operaciones, el resultado de este es depositado en el acumulador de la AUL, si la instrucción ha proporcionado nuevos datos estos son almacenados en la memoria principal y se incrementa en una unidad el contenido del contador de instrucciones a ejecutar.
SUPERVISIÓN
El procesamiento de datos consiste en tomar cada una de las instrucciones y/o datos de un programa y procesarlos, haciéndolos pasar por la unidad aritmética y lógica bajo la supervisión de la unidad de control hasta obtener el resultado deseado. Dicho resultado es almacenado en la memoria principal de manera temporal y puede ser almacenado de modo permanente en un dispositivo de almacenamiento; también puede ser conducido, bajo la supervisión de la unidad de control de periféricos, al dispositivo periférico correspondiente.
ELEMENTOS
La unidad de control (UC) es uno de los tres bloques funcionales principales en los que se divide una unidad central de procesamiento (CPU). Los otros dos bloques son laUnidad de proceso y el bus de entrada/salida.
Su función es buscar las instrucciones en la memoria principal, decodificarlas (interpretación) y ejecutarlas, empleando para ello la unidad de proceso.
Existen dos tipos de unidades de control, las cableadas, usadas generalmente en máquinas sencillas, y las microprogramadas, propias de máquinas más complejas. En el primer caso, los componentes principales son el circuito de lógica secuencial, el de control de estado, el de lógica combinacional y el de emisión de reconocimiento de señales de control. En el segundo caso, la microprogramación de la unidad de control se encuentra almacenada en una micromemoria, a la cual se accede de manera secuencial (1, 2, ..., n) para posteriormente ir ejecutando cada una de las microinstrucciones.
RELOJ
Consiste en un circuito eléctrico capaz de generar una sucesión de pulsos a intervalos de tiempo constantes El intervalo entre dos puntos de reloj se denomina ciclo, en determinados computadores el ciclo puede descomponerse en subciclos.
Los restantes circuitos de la máquina se sincronizan con estas señales de reloj; así se controla la duración de las distintas instrucciones.
REGISTRÓ CONTADOR DE INSTRUCCIONES
Contador de programa (CP): También denominado registro contador de instrucción, (RCI). Su misión e s controlar el orden de ejecución de las instrucciones del programa, de acuerdo con su contenido. Un programa no siempre ejecuta las instrucciones secuencialmente. Puede haber instrucciones de salto o bifurcación.
REGISTRO DE INSTRUCCIONES
(RI): es una unidad de almacenamiento temporal, este registro guarda la instrucción cunado se extrae de la memoria principal y se mantiene mientras se realiza la decodificación o interpretación.
DECODIFICADOR
Habitualmente, toda instrucción contiene un campo conocido como código de operación (co), que indica el tipo de operación que hay que realizar; el decodificador es el elemento encargado de realizar el análisis del código de operación.
SECUENCIADOR
Es un generador de órdenes simples, denominadas microórdenes que sincronizadas con el reloj y distribuidas a los elementos necesarios permiten la ejecución de la instrucción.
Hay dos tipos de Secuenciadores:
Secuenciador Cableados: todas las señales se generan con circuitos lógicos electrónicos. Siempre se producen las mismas señales ante la misma instrucción. Son las mas rápidas pero menos flexibles y mas difíciles de construir.
Secuenciador Programados: tienen una pequeña memoria que contiene un microprograma que se ejecuta para cada sentencia de programa. Las instrucciones de los microprogramas se denominan microinstrucciones
BANCO DE REGISTRO
Aparte de los registros anteriormente explicados, bajo el control de la UC existe otro banco de registros imprescindibles para la realización de cualquier programa. Estos registros se utilizan para conservar datos temporales.
DESCENTRALIZACIÓN DE FUNCIONES Y NUEVAS TECNOLOGÍAS
En este modelo debe existir un equilibrio de poderes entre las divisiones que reciben una descentralización vertical paralela, los analistas de la tecnoestructura que diseñan los sistemas de control de las divisiones, con descentalización horizontal selectiva y la unidad central que retiene la dirección estratégica, y las funciones que se estiman que se pueden ejercer mejor de manera centralizada.
Los rasgos básicos de este tipo de estructura son:
-
La especialización, en grandes unidades o disiviones, dependerá de las decisiones de carácter estratégico.
-
La formalización del comportamiento será elevada y se realiza por resultados para cada una de las divisiones.
-
La descentralización es especialmente vertical paralela con parte de horizontal selectiva. Hemos visto que las unidades van a funcionar de manera autónoma y se controlará su resultado.
-
La agrupación en unidades se hará según diferentes criterios siendo los más frecuentes los de producto, área geográfica, mercado y función.
-
El staff de asesoramiento puede ser importante para el ápice estratégico, sobre todo cuantas más decisiones conjuntas tenga que tomar la alta dirección. La tecnoestructura será pequeña, y estará encargada de diseñar los sistemas de control de las divisiones.
-
El control de la alta dirección sobre las unidades es total por lo que se puede afirmar que existirán pocos niveles jerárquicos y la estructura será chata.
-
Se cuenta con sistemas de planificación y control integrados y se recurre a la dirección por objetivos. El uso de mecanismos de enlace es relativamente importante.
UNIDAD ARITMÉTICO \LÓGICA
En computación, la unidad aritmético lógica, también conocida como ALU (siglas en inglés de arithmetic logic unit), es un circuito digital que calcula operaciones aritméticas (como suma, resta, multiplicación, etc.) y operaciones lógicas (si, y, o, no), entre dos números.
Muchos tipos de circuitos electrónicos necesitan realizar algún tipo de operación aritmética, así que incluso el circuito dentro de un reloj digital tendrá una ALU minúscula que se mantiene sumando 1 al tiempo actual, y se mantiene comprobando si debe activar el sonido de la alarma, etc.
Por mucho, los más complejos circuitos electrónicos son los que están construidos dentro de los chips de microprocesadores modernos. Por lo tanto, estos procesadores tienen dentro de ellos un ALU muy complejo y potente. De hecho, un microprocesador moderno (y losmainframes) puede tener múltiples núcleos, cada núcleo con múltiples unidades de ejecución, cada una de ellas con múltiples ALU.
Muchos otros circuitos pueden contener en el interior una unidad aritmético lógica: unidades de procesamiento gráfico como las que están en las GPU modernas, FPU como el viejo coprocesador matemático 80387, y procesadores digitales de señales como los que se encuentran en tarjetas de sonido, lectoras de CD y los televisores de alta definición. Todos éstos tienen en su interior varias ALU potentes y complejas.
OPERACIONES BÁSICAS
Operaciones simples
La mayoría de las ALU pueden realizar las siguientes operaciones:
-
Operaciones aritméticas de números enteros (adición, sustracción, y a veces multiplicación y división, aunque ésto es más complejo)
-
Operaciones lógicas de bits (AND, NOT, OR, XOR, XNOR)
-
Operaciones de desplazamiento de bits (Desplazan o rotan una palabra en un número específico de bits hacia la izquierda o la derecha, con o sin extensión de signo). Los desplazamientos pueden ser interpretados como multiplicaciones o divisiones por 2.
Operaciones complejas
Un ingeniero puede diseñar una ALU para calcular cualquier operación, sin importar lo compleja que sea; el problema es que cuanto más compleja sea la operación, tanto más costosa será la ALU, más espacio usará en el procesador, y más energía disipará, etc.
Por lo tanto, los ingenieros siempre calculan un compromiso, para proporcionar al procesador (u otros circuitos) una ALU suficientemente potente para calcular rápido, pero no de una complejidad de tal calibre que haga una ALU económicamente prohibitiva. Imagina que necesitas calcular, digamos, la raíz cuadrada de un número; el ingeniero digital examinará las opciones siguientes para implementar esta operación:
-
Diseñar una ALU muy compleja que calcule la raíz cuadrada de cualquier número en un solo paso. Esto es llamado cálculo en un solo ciclo de reloj.
-
Diseñar una ALU compleja que calcule la raíz cuadrada con varios pasos (como el algoritmo que aprendimos en la escuela). Esto es llamado cálculo interactivo, y generalmente confía en el control de una unidad de control compleja con microcódigo incorporado.
-
Diseñar una ALU simple en el procesador, y vender un procesador separado, especializado y costoso, que el cliente pueda instalar adicional al procesador, y que implementa una de las opciones de arriba. Esto es llamado coprocesador o unidad de coma flotante.
-
Emular la existencia del coprocesador, es decir, siempre que un programa intente realizar el cálculo de la raíz cuadrada, hacer que el procesador compruebe si hay presente un coprocesador y usarlo si lo hay; si no hay uno, interrumpir el proceso del programa e invocar al sistema operativo para realizar el cálculo de la raíz cuadrada por medio de un cierto algoritmo de software. Esto es llamado emulación por software.
-
Decir a los programadores que no existe el coprocesador y no hay emulación, así que tendrán que escribir sus propios algoritmos para calcular raíces cuadradas por software. Esto es realizado por bibliotecas de software.
Las opciones superiores van de la más rápida y más costosa a la más lenta y económica. Por lo tanto, mientras que incluso la computadora más simple puede calcular la fórmula más complicada, las computadoras más simples generalmente tomarán un tiempo largo porque varios de los pasos para calcular la fórmula implicarán las opciones #3, #4 y #5 de arriba.
Los procesadores complejos como el Pentium IV y el AMD Athlon 64 implementan la opción #1 para las operaciones más complejas y la más lenta #2 para las operaciones extremadamente complejas. Eso es posible por la capacidad de construir ALU muy complejas en estos procesadores.
UNIDAD ARITMÉTICA
Esta unidad realiza cálculos (suma, resta, multiplicación y división) y operaciones lógicas (comparaciones). Transfiere los datos entre las posiciones de almacenamiento.
Tiene un registro muy importante conocido como: Acumulador ACC Al realizar operaciones aritméticas y lógicas, la UAL mueve datos entre ella y el almacenamiento. Los datos usados en el procesamiento se transfieren de su posición en el almacenamiento a la UAL.
Los datos se manipulan de acuerdo con las instrucciones del programa y regresan al almacenamiento. Debido a que el procesamiento no puede efectuarse en el área de almacenamiento, los datos deben transferirse a la UAL. Para terminar una operación puede suceder que los datos pasen de la UAL al área de almacenamient o varias veces.
ARITMÉTICA BINARIA Y DE UNIDAD HERMÉTICA
Operaciones elementales con números binarios
Suma de números binariosResta de números binarios
-
Complemento a dos
-
Complemento a uno
-
Restar con el complemento a dos
Multiplicar números binariosDividir números binarios
La Unidad Aritmético Lógica, en la CPU del procesador, es capaz de realizar operaciones aritméticas, con datos numéricos expresados en el sistema binario. Naturalmente, esas operaciones incluyen la adición, la sustracción, el producto y la división. Las operaciones se hacen del mismo modo que en el sistema decimal, pero debido a la sencillez del sistema de numeración, pueden hacerse algunas simplificaciones que facilitan mucho la realización de las operaciones.
SISTEMAS PARA LAS OPERACIONES
Para que la unidad aritmética y lógica sea capaz de realizar una operación aritmética, se le deben proporcionar, de alguna manera, los siguientes datos:
1. El código que indique la operación a efectuar.
2. La dirección de la celda donde está almacenado el primer sumando.
3. La dirección del segundo sumando implicado en la operación.
4. La dirección de la celda de memoria donde se almacenará el resultado.
UNIDAD LÓGICA
A medida que cae el precio de los soportes informáticos y se necesita mas capacidad de almacenamiento, algunos usuarios pueden partir un disco duro físico en dos o más unidades de almacenamiento virtual, conocidas como unidades lógicas. Aunque estas unidades virtuales en realidad residen en una pieza del equipo de almacenamiento físico, se ponen en uso práctico como una serie de pequeñas unidades de disco separadas. Este artículo explorará cómo una unidad física se divide en varias unidades, algunos de los beneficios de la utilización de las unidades lógicas, algunas ideas falsas y algunas consideraciones al utilizar estas zonas de almacenamiento.
Función
Cuando un disco duro nuevo es entregado por el fabricante e instalado en un ordenador, el disco nuevo está libre de cualquier formato u otras operaciones específicas del usuario. Para utilizar la unidad, el usuario debe realizar un formateo físico de la unidad (para que esté listo para el funcionamiento), entonces se hace un formato lógico (para prepararlo para su uso en el entorno operativo y apoyar las estructuras de archivos correctos). Cuando el formateo lógico se lleva a cabo, el disco puede ser dividido en varias unidades lógicas, las áreas del disco están lógicamente separadas por la información y el ordenador lee los datos como unidades de disco separadas. Cuando el ordenador del usuario (o los ordenadores de una red) se conectan a la unidad, la formateo lógico hace que la vean como una serie de dispositivos de almacenamiento en lugar de un disco duro sólido. Mientras que los datos almacenados en el disco se almacenan físicamente en los mismos dispositivos, los ordenadores que ven el disco como varias divisiones lógicas, sólo pueden acceder a las unidades lógicas con las que están asociados.
Beneficios
La división de la unidad lógica de almacenamiento del ordenador ayuda a servir a una variedad de propósitos. Los usuarios que no quieren mezclar datos (separar los archivos personales de los datos confidenciales de la empresa, por ejemplo) pueden utilizar por separado cada unidad lógica, casi como dos entornos informáticos distintos. Los usuarios que quieran utilizar dos sistemas operativos (OS), como Microsoft Windows y Linux o Macintosh OS X, puedeninstalar un sistema operativo en cada unidad lógica con el fin de mantener los tipos de archivos incompatibles separados. Además, varios usuarios de la red pueden conectarse a su propia unidad lógica distinta, manteniendo sus datos individuales separados y protegidos de todos los usuarios (excepto el administrador de la red).
OPERACIONES LÓGICAS
Combinando proposiciones simples obtenemos proposiciones compuestas mediante operaciones lógicas.
Las principales operaciones lógicas son: conjunción, disyunción, negación, condicional y Bicondicional.
A cada una de estas operaciones lógicas le corresponde una tabla de verdad.
Conjunción. Dos proposiciones simples p y q relacionadas por el conectivo lógico "y" conforman la proposición compuesta llamada conjunción, la cual se simboliza así: p Ù q.
Disyunción. Dos proposiciones simples p y q relacionadas por el conectivo lógico "O" conforman la proposición compuesta llamada disyunción, la cual se simboliza así: p Ú q.
~ p se lee: no p o también: no es cierto que p
Negación. Dada una proposición simple p, esta puede ser negada y convertirse en otra proposición llamada negación de p, la cual se simboliza así:
Condicional o Implicativa. Dos proposiciones simples p y q relacionadas por el conectivo lógico "entonces" conforman la proposición compuesta llamada condicional o implicativa, la cual se simboliza así: p Þ q:
Bicondicional. Dos proposiciones simples p y q relacionadas por el conectivo lógico "si y sólo si" conforman la proposición compuesta llamada conjunción, la cual se simboliza así: p « q.





LÓGICA DIGITAL DE UNIDAD LÓGICA
La manera en que una unidad lógica es identificada a la computadora de un usuario depende de cómo ese ordenador esté accediendo a la unidad. En una típica configuración hecha en casa donde un Windows puede acceder a muchas unidades lógicas, la identificación de una unidad es asignada por el orden en que la unidad es mapeada (el primer disco duro normalmente se le asigna una letra de C, la siguiente unidad se denomina D, y así sucesivamente). Los usuarios de Macintosh y Linux / UNIX pueden identificar la unidad mediante la asignación de un nombre legible para ellos como "mi disco duro", "Mi segunda unidad de disco", "Mi unidad de amigos". En un negocio, un cliente ligero, o un entorno de red grande donde el usuario sólo tiene acceso a una única unidad lógica, esta unidad es generalmente considerado por el cliente de red como unidad de almacenamiento disponible y sólo se trata como si fuera un disco en solitario instalado en la máquina (aunque los usuarios de la red UNIX o Macintosh pueden ver el nombre asignado a la unidad por el administrador de red).
BUSES
El bus (o canal) es un sistema digital que transfiere datos entre los componentes de una computadora o entre computadoras. Está formado por cables o pistas en un circuito impreso, dispositivos como resistores y condensadores además de circuitos integrados.
El propósito de los buses es reducir el número de rutas necesarias para la comunicación entre los distintos componentes, al realizar las comunicaciones a través de un solo canal de datos. Ésta es la razón por la que, a veces, se utiliza la metáfora "autopista de datos".
Un bus se caracteriza por la cantidad de información que se transmite en forma simultánea. Este volumen se expresa en bits y corresponde al número de líneas físicas mediante las cuales se envía la información en forma simultánea.
La velocidad del bus se define a través de su frecuencia (que se expresa en Hercios o Hertz), es decir el número de paquetes de datos que pueden ser enviados o recibidos por segundo. Cada vez que se envían o reciben estos datos podemos hablar de ciclo.
4 BIT DE BUS
En arquitectura de ordenadores, 4 bits es un adjetivo usado para describir enteros, direcciones de memoria u otras unidades de datos que comprenden hasta 4 bits de ancho, o para referirse a una arquitectura de CPU y ALU basadas en registros, bus de direcciones o bus de datos de ese ancho.
El Intel 4004, el primer microprocesador comercial de único chip, fue una CPU de 4 bits.
8 BIT BUS
Las CPU de 8 bits normalmente usan un bus de datos de 8 bits y un bus de direcciones de 16 bits lo que causa que su memoria direccionable esté limitada a 64 kilobytes; sin embargo esto no es una "ley natural", ya que existen excepciones.
El primer microprocesador de 8 bits ampliamente utilizado es el Intel 8080, que se usó en computadores de aficionados a finales de los años 1970 y principio de los años 1980, muchos corriendo el sistema operativo CP/M.
16 BIT O ISA BUS
Abreviatura de (Arquitectura estándar de la industria). Diseño del BUS de 16 bits utilizado por primera vez en las computadoras PC/AT de IBM. La Arquitectura estándar extendida de la industria (EISA), es una extensión de 32 bits que fue hecha a este estándar de BUS en 1984. La arquitectura estándar de la industria o ISA tiene una velocidad de BUS de 8 MHz, y un caudal de procesamiento (de datos) máximo de 8 megabytes por segundo.
32 BIT O EISA BUS
(Arquitectura estándar extendida de la industria). BUS estándar de una computadora personal que extiende el BUS AT tradicional a 32 bits y le permite a más de un procesador compartir el BUS. La Arquitectura estándar extendida de la industria (EISA), fue desarrollada por la llamada Pandilla de Nueve en respuesta a la introducción, por IBM.
El bus de direcciones es un canal del microprocesador totalmente independiente del bus de datos donde se establece la dirección de memoria del dato en tránsito.
El bus de dirección consiste en el conjunto de líneas eléctricas necesarias para establecer una dirección.
INSTRUCCIONES
Cada ciclo en la CPU capta una instrucción de memoria. En una CPU utiliza un registro llamado contador de programa (PC) para seguir la pista dela instrucción.
La secuencia de operaciones realizadas en la ejecución de una instrucción constituye lo que se denomina ciclo de instrucción
Lo más cómodo es considerar que el procesamiento del ciclo de instrucción consta de dos fases:
-
Fase de búsqueda
-
Fase de ejecución
Fase de búsqueda:
1.-Transferir el contenido del Contador de Programa (CP) al registro de Direcciones(RD).
2.-Pasar a registro de Memoria (RM) el dato almacenado en la dirección de memoria indicada por RD.
3.-Transferir el dato leído desde el RM al registro de instrucción (RI).4.
Fase de ejecución:
5. Decodificación de la Instrucción. Por ejemplo la Instrucción ADD.
6. Transferencia del campo CD de la instrucción en curso (este campo contiene la dirección de memoria en la que se encuentra el operando, y que se encuentra en el registro RI desde que finalizó la fase de búsqueda), al registro RD.
Se inicia, por tanto, un proceso similar al de la fase de búsqueda, pero en esta ocasión para buscar en memoria el operando de la instrucción.
7. Lanzar un ciclo de lectura de memoria que ponga en RM el operando almacenado en la dirección indicada por RD.
8. Transferencia del dato leído desde el RM al registro intermedio, Ro2, del Operador. Paralelamente se puede transferir el otro operando desde el acumulador, AC, (contenido en él un instante anterior), al registro intermedio Ro1.9.
Realizar la operación de SUMA (ADD) y almacenar el resultado en el AC.
CODIGO DE OPERACIÓN
Es la porción de una instrucción de lenguaje de máquina que especifica la operación a ser realizada. Su especificación y formato serán determinados por la arquitectura del conjunto de instrucciones (ISA) del componente de hardware de computador - normalmente un CPU, pero posiblemente una unidad más especializada.
Una instrucción completa de lenguaje de máquina contiene un opcode y, opcionalmente, la especificación de uno o más operando - sobre los que la operación debe actuar.
DIRECCIONES
Es un canal del microprocesador totalmente independiente del bus de datos donde se establece la dirección de memoria del dato en tránsito.
El bus de dirección consiste en el conjunto de líneas eléctricas necesarias para establecer una dirección. La capacidad de la memoria que se puede direccionar depende de la cantidad de bits que conforman el bus de direcciones, siendo 2n el tamaño máximo en bits del banco de memoria que se podrá direccionar con n líneas.
En el diagrama se ven los buses de dirección, datos, y control, que van desde la unidad central de procesamiento a la memoria de acceso aleatorio, la memoria de solo lectura, la entrada/salida.
INSTRUCCIONES DE UNA DIRECCION, DOS Y TRES
La clase de operación a realizar, en este caso una suma; es el papel del código de operación;
2) la dirección de la celda de memoria que contiene el primer dato, o primer operando;
3) la dirección de la celda de memoria que contiene el segundo operando;
4) la dirección de la celda de memoria donde quiere almacenarse el resultado.
Se deduce la forma de instrucción que contiene un código y tres direcciones:
La operación de suma necesita tres instrucciones para:
1) cargar el primer operando en el acumulador;
2) sumar el segundo operando con el contenido del acumulador;
3) almacenar en memoria el contenido del acumulador.


Cada una de estas tres instrucciones comportará un código de operación y una dirección:

MEMORIA VIRTUAL
La memoria virtual es una técnica de gestión de la memoria que permite que el sistema operativo disponga, tanto para el software de usuario como para sí mismo, de mayor cantidad de memoria que la disponible físicamente. La mayoría de los ordenadores tienen cuatro tipos de memoria: registros en la CPU, la memoria caché (tanto dentro como fuera del CPU), la memoria RAM y el disco duro. En ese orden, van de menor capacidad y mayor velocidad a mayor capacidad y menor velocidad.
OPERACIÓN BÁSICA
Cuando se usa memoria virtual, o cuando una dirección es leída o escrita por la CPU, una parte del hardware dentro de la computadora traduce las direcciones de memoria generadas por el software (direcciones virtuales) en:
La dirección real de memoria (la dirección de memoria física).
Una indicación de que la dirección de memoria deseada no se encuentra en memoria principal (llamado excepción de memoria virtual)
NECESIDAD DE LA MEMORIA VIRTUAL
Si nos quedamos sin memoria no podremos ejecutar más programas y los que estamos ejecutando tendrán problemas para trabajar con más datos. Además, el uso de memoria virtual puede hacer que tu equipo funcione más lento si es necesario ir por datos al disco duro. Es siempre un compromiso entre la velocidad y la cantidad de datos que el sistema es capaz de procesar.
Jamás una configuración de más memoria virtual podrá ser mejor que una ampliación de memoria RAM. Es más, lo ideal sería tener un equipo que no necesitase tener esta característica activada.
PAGINACIÓN
En sistemas operativos de computadoras, los sistemas de paginación de memoria dividen los programas en pequeñas partes o páginas. Del mismo modo, la memoria es dividida en trozos del mismo tamaño que las páginas llamados marcos de página. De esta forma, la cantidad de memoria desperdiciada por un proceso es el final de su última página, lo que minimiza la fragmentación interna y evita la externa.
TABLA DE PAGINACIÓN
Las tablas de paginación o tablas de páginas son una parte integral del Sistema de Memoria Virtual en sistemas operativos, cuando se utiliza paginación. Son usadas para realizar las traducciones de direcciones de memoria virtual (o lógica) a memoria real (o física) y en general el sistema operativo mantiene una por cada proceso corriendo en el sistema.
CARGA DE PÁGINAS
En la tabla de páginas de un proceso, se encuentra la ubicación del marco que contiene a cada una de sus páginas. Las direcciones lógicas ahora se forman como un número de página y de un desplazamiento dentro de esa página (conocido comúnmente como offset). El número de página es usado como un índice dentro de la tabla de páginas, y una vez obtenida la dirección del marco de memoria, se utiliza el desplazamiento para componer la dirección real o dirección física.
Este proceso se realiza en una parte del computador específicamente diseñada para esta tarea, es decir, es un proceso hardware y no software.
De esta forma, cuando un proceso es cargado en memoria, se cargan todas sus páginas en marcos libres y se completa su tabla de páginas.
METODO FIFO
Primera en entrar, primera en salir. Supone que una página introducida hace mucho tiempo puede haber caído en desuso Cuando se produce un FdP. y no hay marcos libres, se quita la página que lleve más tiempo en memoria Buffer circular de marcos de un proceso + puntero Round Robin para eliminar páginas de memoria Sencillo de implementar
Puede no ser efectivo:
Regiones muy usadas durante toda la ejecución
Método LRU
-
Página usada hace más tiempo
(Least Recently Used)
-
Basado en Principio de Cercanía
-
Mirar al pasado y estimar cuál podría ser el uso de la página en función de él
FRAGMENTACIÓN
Los métodos de administración de la memoria principal, que no utilizan Memoria Virtual y esquemas de Paginación y Segmentación, es decir que llevan a las direcciones directamente al bus de la memoria, tienen un inconveniente: producen lo que se denomina fragmentación.
La fragmentación, que son huecos en la memoria que no pueden usarse debido a lo pequeño de su espacio, provoca un desperdicio de memoria principal.
Una posible solución para la fragmentación externa es permitir que espacio de direcciones lógicas lleve a cabo un proceso en direcciones no contiguas, así permitiendo al proceso ubicarse en cualquier espacio de memoria física que esté disponible, aunque esté dividida. Una forma de implementar esta solución es a través del uso de un esquema de paginación. La paginación evita el considerable problema de ajustar los pedazos de memoria de tamaños variables que han sufrido los esquemas de manejo de memoria anteriores. Dado a sus ventajas sobre los métodos previos, la paginación, en sus diversas formas, es usada en muchos sistemas operativos.
EVOLUCIÓN DE LOS COMPONENTES DE UN SISTEMA DE PROGRAMACIÓN
ENSAMBLADOR
El lenguaje ensamblador constituye el primer intento de sustitución del lenguaje máquina por uno más cercano al usado por los humanos. Este acercamiento a las personas se plasma en las siguientes aportaciones:
Uso de una notación simbólica o nemotécnica para representar los códigos de operación
Direccionamiento simbólico
Se permite el uso de comentarios entre las líneas de instrucciones, haciendo posible la redacción de programas más legibles.
Aparte de esto él LE presenta la mayoría de los inconvenientes del lenguaje máquina, como son su repertorio muy reducido de instrucciones, el rígido formato de instrucciones, la baja potabilidad y la fuerte dependencia del hardware. Por otro lado mantiene la ventaja del uso óptimo de los recursos hardware, permitiendo la obtención de un código muy eficiente.
Ese tipo de lenguajes hacen corresponder a cada instrucción en ensamblador una instrucción en código máquina. Esta transducción es llevada a cabo por un programa traductor denominado Ensamblador.
Para solventar en cierta medida la limitación que supone poseer un repertorio de instrucciones, tan reducido, se han desarrollado unos ensambladores especiales denominados macroensambladores.
Los lenguajes que traducen los macroensambladores disponen de macroinstrucciones cuya traducción da lugar a varias instrucciones máquina y no a una sola.
Dado que el lenguaje ensamblador es6ta fuertemente condicionado por la arquitectura del ordenador que soporta, los programadores no suelen escribir programas de tamaño considerable en ensamblador. Más bien usan este lenguaje para afinar partes importantes de programas escritos en lenguajes de más alto nivel.
Como señalado a propósito del "Primer Nivel" de los lenguajes, el Ensamblador es directamente dependiente de los circuitos electrónicos de los procesadores (que constituyen el núcleo de los computadoras), por lo cual escribir en Ensamblador sigue siendo una tarea muy compleja, a lo cual hay que sumar que el código varía de un procesador a otro aunque existe ya una jerga común para ciertas operaciones como las aritméticas y lógicas, por ejemplo:
ADD para sumar (sin reserva) ADC para sumar con reserva ("add with carry") M para multiplicar ORA para él "o" lógico ("or and") EOR para él "o" exclusivo (o bien... o bien...)
Las instrucciones de este tipo deben ir seguidas sea de dos valores (dos números a sumar o multiplicar por ejemplo) o del nombre de una variable. Cuando se ejecute el programa, el valor de una variable nombrada deberá provenir de una operación anterior que haya terminado por una instrucción del tipo "almacenar el resultado de la operación en la variable X", haya extraído el valor de la variable de una determinada celda de memoria, o Haya efectuado una interacción con el usuario, por ejemplo escribir en pantalla "Escriba el valor de X".
(Estas son "instrucciones de asignación").
El Ensamblador contiene además un conjunto mínimo de instrucciones de alternación e iteración indispensables para que un programa pueda funcionar como tal.
CARGADORES
Un cargador es un programa del sistema que realiza la función de carga, pero muchos cargadores también incluyen relocalización y ligado. Algunos sistemas tienen un ligador para realizar las operaciones de enlace, y un cargador separado para manejar la relocalización y la carga. Los procesos de ensamblado y carga están íntimamente relacionados.
Las funciones más importantes de un cargador son: colocar un programa objeto en la memoria e iniciar su ejecución. Si tenemos un cargador que no necesita realizar las funciones de ligado y relocalización de programas, su operación es muy simple, pues todas las funciones se realizan en un solo paso. Se revisa el registro de encabezamiento para comprobar se ha presentado el programa correcto para la carga (entrando en la memoria disponible). A medida que se lee cada registro de texto, el código objeto que contiene pasa a la dirección de memoria indicada. Cuando se encuentra el registro de fin, el cargador salta a la dirección especificada para iniciar la ejecución del programa cargado.
Un programa objeto contiene instrucciones traducidas y valores de datos del programa fuente, y específica direcciones en memoria donde se cargarán estos elementos.
Carga, que lleva el programa objeto a la memoria para su ejecución.
Relocalización, que modifica el programa objeto de forma que puede cargarse en una dirección diferente de la localidad especificada originalmente.
Ligado, que combina dos o más programas objeto independientes y proporciona la información necesaria para realizar referencias entre ellos.
Un cargador es un programa del sistema que realiza la función de carga, pero muchos cargadores también incluyen relocalización y ligado. Algunos sistemas tienen un ligador( o editor de ligado) para realizar las operaciones de enlace, y un cargador separado para manera la relocalización y la carga.
COMPILADORES
Un compilador es un programa informático que traduce un programa escrito en un lenguaje de programación a otro lenguaje de programación, generando un programa equivalente que la máquina será capaz de interpretar. Usualmente el segundo lenguaje es lenguaje de máquina, pero también puede ser un código intermedio (bytecode), o simplemente texto. Este proceso de traducción se conoce como compilación.1
Un compilador es un programa que permite traducir el código fuente de un programa en lenguaje de alto nivel, a otro lenguaje de nivel inferior (típicamente lenguaje de máquina). De esta manera un programador puede diseñar un programa en un lenguaje mucho más cercano a cómo piensa un ser humano, para luego compilarlo a un programa más manejable por una computadora.

SISTEMAS FORMALES
Un sistema formal es un tipo de sistema lógico-deductivo constituido por un lenguaje formal, una gramática formal que restringe cuales son las expresiones correctamente formadas de dicho lenguaje y las reglas de inferencia y un conjunto de axiomas que permite encontrar las proposiciones derivables de dichos axiomas. Los sistemas formales también han encontrado aplicación dentro de la informática, la teoría de la información, y la estadística, para proporcionar una definición rigurosa del concepto de demostración. La noción de sistema formal corresponde a una formalización rigurosa y completa del concepto de sistema axiomático.
Llamamos formalización al acto de crear un sistema formal, con la que pretendemos capturar y abstraer la esencia de determinadas características del mundo real, en un modelo conceptual expresado en un determinado lenguaje formal.
En matemáticas, las demostraciones formales pueden expresarse en el lenguaje de los sistemas formales, consistentes en axiomas y reglas de inferencia. Los teoremas pueden ser obtenidos por medio de demostraciones formales. Este punto de vista de las matemáticas ha sido denominado formalista; aunque en muchas ocasiones este término conlleva una acepción peyorativa. En ese sentido David Hilbert creó la disciplina denominada metamatemática dedicada al estudio de los sistemas formales, entendiendo que el lenguaje utilizado para ello, denominado metalenguaje era distinto del lenguaje del sistema formal que se pretendía estudiar. Con otra denominación, el metalenguaje o lenguaje obtenido mediante la gramática formal se llama también, en ocasiones, lenguaje objeto.
EVOLUCION DE LOS SISTEMAS OPERATIVOS
Un sistema operativo es un conjunto de programas destinado a permitir el uso apropiado de las partes físicas del ordenador (hardware).
Los sistemas operativos proveen un conjunto de funciones necesarias y usadas por diversos programas de aplicaciones de una computadora, y los vínculos necesarios para controlar y sincronizar el hardware de la misma. En las primeras computadoras, que no tenían sistema operativo cada programa necesitaba la más detallada especificación del hardware para ejecutarse correctamente y desarrollar tareas estándares, y sus propios drivers para los dispositivos periféricos como impresoras y lectores de tarjetas perforadas. El incremento de la complejidad del hardware y los programas de aplicaciones eventualmente hicieron del sistema operativo una necesidad.
Los primeros sistemas operativos fueron desarrollados por cada usuario para adecuar el uso de su propia computadora central, y es en 1956 que la General Motors desarrolla lo que es hoy considerado el primer sistema, el GM-NAA I/O, para su IBM 704.
LA DÉCADA DE 1940
A finales de la década de 1940, con lo que se podría considerar la aparición de la primera generación de computadoras, se accedía directamente a la consola de la computadora desde la cual se actuaba sobre una serie de micro interruptores que permitían introducir directamente el programa en la memoria de la computadora (en realidad al existir tan pocas computadoras todos podrían considerarse prototipos y cada constructor lo hacía sin seguir ningún criterio predeterminado). Por aquel entonces no existían los sistemas operativos, y los programadores debían interactuar con el hardware del computador sin ayuda externa. Esto hacía que el tiempo de preparación para realizar una tarea fuera considerable. Además para poder utilizar la computadora debía hacerse por turnos. Para ello, en muchas instalaciones, se rellenaba un formulario de reserva en el que se indicaba el tiempo que el programador necesitaba para realizar su trabajo. En aquel entonces las computadoras eran máquinas muy costosas lo que hacía que estuvieran muy solicitadas y que sólo pudieran utilizarse en periodos breves de tiempo. Todo se hacía en lenguaje de máquina.
LA DÉCADA DE 1950 (SISTEMA BATCH)
A principios de los años 50 con el objeto de facilitar la interacción entre persona y computadora, los sistemas operativos hacen una aparición discreta y bastante simple, con conceptos tales como el monitor residente, el proceso por lotes y el almacenamiento temporal.
Monitor residente
Su funcionamiento era bastante simple, se limitaba a cargar los programas a memoria, leyéndolos de una cinta o de tarjetas perforadas, y ejecutarlos. El problema era encontrar una forma de optimizar el tiempo entre la retirada de un trabajo y el montaje del siguiente.
Procesamiento por lotes
Como solución para optimizar, en una misma cinta o conjunto de tarjetas, se cargaban varios programas, de forma que se ejecutaran uno a continuación de otro sin perder apenas tiempo en la transición.
Almacenamiento temporal
Su objetivo era disminuir el tiempo de carga de los programas, haciendo simultánea la carga del programa o la salida de datos con la ejecución de la siguiente tarea. Para ello se utilizaban dos técnicas, el buffering y el spooling.
LA DÉCADA DE 1960
En los años 60 se produjeron cambios notorios en varios campos de la informática, con la aparición del circuito integrado la mayoría orientados a seguir incrementando el potencial de los ordenadores. Para ello se utilizaban técnicas de lo más diversas.
Multiprogramación
En un sistema multi programado la memoria principal alberga a más de un programa de usuario. La CPU ejecuta instrucciones de un programa, cuando el que se encuentra en ejecución realiza una operación de E/S; en lugar de esperar a que termine la operación de E/S, se pasa a ejecutar otro programa. Si éste realiza, a su vez, otra operación de E/S, se mandan las órdenes oportunas al controlador, y pasa a ejecutarse otro. De esta forma es posible, teniendo almacenado un conjunto adecuado de tareas en cada momento, utilizar de manera óptima los recursos disponibles.
Tiempo compartido
Artículo principal: Tiempo compartido.
En este punto tenemos un sistema que hace buen uso de la electrónica disponible, pero adolece la falta de interactividad; para conseguirla debe convertirse en un sistema multiusuario, en el cual existen varios usuarios con un terminal en línea, utilizando el modo de operación de tiempo compartido. En estos sistemas los programas de los distintos usuarios residen en memoria. Al realizar una operación de E/S los programas ceden la CPU a otro programa, al igual que en la multiprogramación. Pero, a diferencia de ésta, cuando un programa lleva cierto tiempo ejecutándose el sistema operativo lo detiene para que se ejecute otra aplicación.
Tiempo real
Estos sistemas se usan en entornos donde se deben aceptar y procesar en tiempos muy breves un gran número de sucesos, en su mayoría externos al ordenador. Si el sistema no respeta las restricciones de tiempo en las que las operaciones deben entregar su resultado se dice que ha fallado. El tiempo de respuesta a su vez debe servir para resolver el problema o hecho planteado. El procesamiento de archivos se hace de una forma continua, pues se procesa el archivo antes de que entre el siguiente, sus primeros usos fueron y siguen siendo en telecomunicaciones.
Multiprocesador
Diseño que no se encuentran en ordenadores monoprocesador. Estos problemas derivan del hecho de que dos programas pueden ejecutarse simultáneamente y, potencialmente, pueden interferirse entre sí. Concretamente, en lo que se refiere a las lecturas y escrituras en memoria. Existen dos arquitecturas que resuelven estos problemas:
La arquitectura NUMA, donde cada procesador tiene acceso y control exclusivo a una parte de la memoria. La arquitectura SMP, donde todos los procesadores comparten toda la memoria. Esta última debe lidiar con el problema de la coherencia de caché. Cada microprocesador cuenta con su propia memoria cache local. De manera que cuando un microprocesador escribe en una dirección de memoria, lo hace únicamente sobre su copia local en caché. Si otro microprocesador tiene almacenada la misma dirección de memoria en su caché, resultará que trabaja con una copia obsoleta del dato almacenado.
Para que un multiprocesador opere correctamente necesita un sistema operativo especialmente diseñado para ello. La mayoría de los sistemas operativos actuales poseen esta capacidad.
Sistemas operativos desarrollados
Además del Atlas Supervisor y el OS/360, los años 1970 marcaron el inicio de UNIX, a mediados de los 60 aparece Multics, sistema operativo multiusuario - multitarea desarrollado por los laboratorios Bell de AT&T y Unix, convirtiéndolo en uno de los pocos SO escritos en un lenguaje de alto nivel. En el campo de la programación lógica se dio a luz la primera implementación de Prolog, y en la revolucionaria orientación a objetos, Smalltalk.
Inconvenientes de los Sistemas operativos
Se trataba de sistemas grandes, complejos y costosos, pues antes no se había construido nada similar y muchos de los proyectos desarrollados terminaron con costos muy por encima del presupuesto y mucho después de lo que se marcaba como fecha de finalización. Además, aunque formaban una capa entre el hardware y el usuario, éste debía conocer un complejo lenguaje de control para realizar sus trabajos. Otro de los inconvenientes es el gran consumo de recursos que ocasionaban, debido a los grandes espacios de memoria principal y secundaria ocupados, así como el tiempo de procesador consumido. Es por esto que se intentó hacer hincapié en mejorar las técnicas ya existentes de multiprogramación y tiempo compartido.
Características de los nuevos sistemas
Sistemas operativos desarrollados
-
MULTICS (Multiplexed Information and Computing Service): Originalmente era un proyecto cooperativo liderado por Fernando Corbató del MIT, con General Electric y los laboratorios Bell, que comenzó en los 60, pero los laboratorios Bell abandonaron en 1969 para comenzar a crear el sistema UNIX. Se desarrolló inicialmente para el mainframe GE-645, un sistema de 36 bits; después fue soportado por la serie de máquinas Honeywell 6180.
Fue uno de los primeros. Además, los traducía a instrucciones de alto nivel destinadas a BDOS.
-
BDOS (Basic Disk Operating System): Traductor de las instrucciones en llamadas a la BIOS.
-
CP/M: (Control Program for Microcomputers) fue un sistema operativo desarrollado por Gary Kildall para el microprocesador Intel 8080 (los Intel 8085 y Zilog Z80 podían ejecutar directamente el código del 8080, aunque lo normal era que se entregara el código recompilado para el microprocesador de la máquina). Se trataba del sistema operativo más popular entre las computadoras personales en los años 70. Aunque fue modificado para ejecutarse en un IBM PC, el hecho que IBM eligiera MS-DOS, al fracasar las negociaciones con Digital Research, hizo que el uso de CP/M disminuyera hasta hacerlo desaparecer. CP/M originalmente significaba Control Program/Monitor. Más tarde fue renombrado a Control Program for Microcomputers. En la época, la barra inclinada (/) tenía el significado de "diseñado para". No obstante, Gary Kildall redefinió el significado del acrónimo poco después. CP/M se convirtió en un estándar de industria para los primeros micro-ordenadores.
El hecho de que, años después, IBM eligiera para sus PC a MS-DOS supuso su mayor fracaso, por lo que acabó desapareciendo.
LA DÉCADA DE 1980
Con la creación de los circuitos LSI -integración a gran escala-, chips que contenían miles de transistores en un centímetro cuadrado de silicio, empezó el auge de los ordenadores personales. En éstos se dejó un poco de lado el rendimiento y se buscó más que el sistema operativo fuera amigable, surgiendo menús, e interfaces gráficas. Esto reducía la rapidez de las aplicaciones, pero se volvían más prácticos y simples para los usuarios. En esta época, siguieron utilizándose lenguajes ya existentes, como Smalltalk o C, y nacieron otros nuevos, de los cuales se podrían destacar: C++ y Eiffel dentro del paradigma de la orientación a objetos, y Haskell y Miranda en el campo de la programación declarativa. Un avance importante que se estableció a mediados de la década de 1980 fue el desarrollo de redes de computadoras personales que corrían sistemas operativos en red y sistemas operativos distribuidos. En esta escena, dos sistemas operativos eran los mayoritarios: MS-DOS (Micro Soft Disk Operating System), escrito por Microsoft para IBM PC y otras computadoras que utilizaban la CPU Intel 8088 y sus sucesores, y UNIX, que dominaba en los ordenadores personales que hacían uso del Motorola 68000.
Mac OS
El lanzamiento oficial del ordenador Macintosh en enero de 1984, al precio de US $1,995 (después cambiado a $2,495 dólares). Incluía su sistema operativo Mac OS cuya características novedosas era una GUI (Graphic User Interface), Multitareas y Mouse. Provocó diferentes reacciones entre los usuarios acostumbrados a la línea de comandos y algunos tachando el uso del Mouse como juguete.
MS-DOS
En 1981 Microsoft compró un sistema operativo llamado QDOS que, tras realizar unas pocas modificaciones, se convirtió en la primera versión de MS-DOS (Micro Soft Disk Operating System). A partir de aquí se sucedieron una serie de cambios hasta llegar a la versión 7.1, versión 8 en Windows Milenium, a partir de la cual MS-DOS dejó de existir como un componente del Sistema Operativo.
Microsoft Windows
A mediados de los años 80 se crea este sistema operativo, pero no es hasta la salida de (Windows 95) que se le puede considerar un sistema operativo, solo era una interfaz gráfica del (MS-DOS) en el cual se disponía de unos diskettes para correr los programas. Hoy en día es el sistema operativo más difundido en el ámbito doméstico aunque también hay versiones para servidores como Windows NT. (Microsoft) ha diseñado también algunas versiones para superordenadores, pero sin mucho éxito. Años después se hizo el (Windows 98) que era el más eficaz de esa época. Después se crearía el sistema operativo de (Windows ME) (Windows Millenium Edition) aproximadamente entre el año 1999 y el año 2000. Un año después se crearía el sistema operativo de (Windows 2000) en ese mismo año. Después le seguiría el sistema operativo más utilizado en la actualidad, (Windows XP) y otros sistemas operativos de esta familia especializados en las empresas. (Windows 7) (Windows Seven) salió al mercado el 22 de octubre del 2009, dejó atrás a (Windows Vista), que tuvo innumerables críticas durante el poco tiempo que duró en el mercado. El más reciente hasta la fecha es (Windows 8) (Windows Eight) lanzado en octubre de 2012.
LA DÉCADA DE 1990
GNU/Linux
Este sistema al parecer es una versión mejorada de Unix, basado en el estándar POSIX, un sistema que en principio trabajaba en modo comandos. Hoy en día dispone de Ventanas, gracias a un servidor gráfico y a gestores de ventanas como KDE, GNOME entre muchos. Recientemente GNU/Linux dispone de un aplicativo que convierte las ventanas en un entorno 3D como por ejemplo Beryl o Compiz. Lo que permite utilizar Linux de una forma visual atractiva.
Existen muchas distribuciones actuales de Gnu/Linux (Debian, Fedora, Ubuntu, Slackware, etc.) donde todas ellas tienen en común que ocupan el mismo núcleo Linux. Dentro de las cualidades de Gnu/Linux se puede caracterizar el hecho de que la navegación a través de la web es sin riegos de ser afectada por virus, esto debido al sistema de permisos implementado, el cual no deja correr ninguna aplicación sin los permisos necesarios, permisos que son otorgados por el usuario. A todo esto se suma que los virus que vienen en dispositivos desmontables tampoco afectan al sistema, debido al mismo sistema de permisos.
ESTRUCTURA DE LA MAQUINA. LENGUAJE ENSAMBLADO
Fue el primer lenguaje utilizado en la programación para las primeras computadoras, pero dejó de utilizarse por su dificultad y complicación, siendo sustituido por otros lenguajes más fáciles de aprender y utilizar.
LENGUAJE DE MÁQUINA
También conocido como código máquina
Es el sistema de códigos directamente interpretable por un circuito micro programable, como el microprocesador de una computadora.
Este lenguaje está compuesto por un conjunto de instrucciones que determinan acciones al ser tomadas por la máquina.
El lenguaje máquina es el único que entiende directamente la computadora, utiliza el alfabeto binario que consta de los dos únicos símbolos 0 y 1, denominados bits.
Todo código fuente en última instancia debe llevarse a un lenguaje máquina mediante el proceso de compilación o interpretación para que la computadora pueda ejecutarlo.

El lenguaje máquina es el único que entiende directamente la computadora, utiliza el alfabeto binario que consta de los dos únicos símbolos 0 y 1, denominados bits.
Todo código fuente en última instancia debe llevarse a un lenguaje máquina mediante el proceso de compilación o interpretación para que la computadora pueda ejecutarlo.
VENTAJAS DEL LENGUAJE MÁQUINA
- Posibilidad de cargar (transferir un programa a la memoria) sin necesidad de traducción posterior, lo que supone una velocidad de ejecución superior a cualquier otro lenguaje de programación.
DESVENTAJAS DEL LENGUAJE MÁQUINA
- Dificultad y lentitud en la codificación.
- Poca fiabilidad.
- Gran dificultad para verificar y poner a punto los programas.
- Los programas solo son ejecutables en el mismo procesador (CPU).
ENSAMBLADORES
PROCEDIMIENTO GENERAL DE DISEÑO
1.- Se puede acceder a cualquier localidad de la memoria RAM sin ninguna restricción.
2.- Se pueden programar virus, debido a que se tiene un acceso total a casi todo el hardware de la computadora vía interrupciones de software.
3.- Se pueden programar drivers de cualquier dispositivo.
4.- Se puede acceder directamente a los registros internos del CPU.
5.- Se puede acceder directamente a los dispositivos de entrada y/o salida.
Los programas objeto generados a través del ensamblador son más veloces que los generados en cualquier otro lenguaje, debido a que una instrucción en ensamblador corresponde a una instrucción en lenguaje máquina.
DISEÑO DE ENSAMBLADOR
El lenguaje ensamblador es un tipo de lenguaje de bajo nivel utilizado para escribir programas informáticos, y constituye la representación más directa del código máquina específico para cada arquitectura de microprocesador.
El uso del lenguaje ensamblador es para profesionistas en el área de computación que están obligados a conocer este lenguaje, ya que proporciona una serie de características que no se pueden encontrar en los lenguajes de alto nivel.
La unidad de procesamiento central (CPU) es donde se manipulan los datos. En una microcomputadora, el CPU completo está contenido en un chip muy pequeño llamado microprocesador.
Todas las CPU tienen por lo menos dos partes básicas, la unidad de control y la unidad aritmética lógica.
Todos los recursos de la computadora son administrados desde la unidad de control, cuya función es coordinar todas las actividades de la computadora.
La unidad de control contiene las instrucciones de la CPU para llevar a cabo comandos. El conjunto de instrucciones, que está incluido dentro de los circuitos de la unidad de control, es una lista de todas las operaciones que realiza la CPU.
PLANTAMIENTO DEL PROBLEMA
Conocer más a fondo, que ventajas se deben tener para el conocimiento de los lenguajes ensamblador, que función tiende a realizar y que tan importante es que se traduzcan a lenguaje máquina.
Dentro de este se sabe que existen diferentes tipos de lenguajes que nos permitirá visualizar en la pantalla la imagen que deseemos.
DEFINICION DEL PROBLEMA
En la actualidad muchos no tienen conocimiento de que función ejerce el lenguaje ensamblador, algunas personas, solo utilizan las computadoras para hacer uso del internet, pero no se ponen a ver qué es lo que aparece en la pantalla.
El lenguaje ensamblador nos va a permitir tener conocimientos de que funciones debe de realizar para que podamos ver la imagen que queremos en nuestra pantalla.
OBJETIVO GENERAL
Dar a conocer cómo es que aparecen las imágenes que estamos visualizando en la pantalla y por qué toman esa forma.
Que muchas personas que puedan tener un conocimiento básico del lenguaje ensamblador, mediante esta información que esperemos que sea de gran utilidad para que en un futuro su uso sea satisfactorio.
También para facilitarles la información y que pueda estar al alcance de todas la gente que quiera adquirir este conocimiento.
ESTRUCTURA DE LOS DATOS
Las estructuras de datos son secciones lineales dentro de la memoria que representan un conjunto de datos.
Una estructura de datos a nivel ensamblador es exactamente igual. Se trata de una zona continua de la memoria que contiene datos. Y al igual que el mapa no hay una verdadera división que defina realmente donde comienza uno y termina otro. Ni siquiera el programa sabe realmente donde se marcan estas divisiones porque todo esto es determinado por el compilador.
ESTRUCTURA DE LAS BASES DE DATOS
Una base de datos de red está formada por una colección de registros, los cuales están conectados entre sí por medio de enlaces.
Registro: Es una colección de campos (atributos)
Campos: Contiene almacenado solamente un valor.
Enlace.- Asociación entre dos registros, así que podemos verla como una relación estrictamente binaria.
Estructura de datos de red, abarca más que la estructura de árbol porque un nodo "hijo" en la estructura de red puede tener más de un padre.
Diagramas de estructura de datos.
Es un esquema que representa el diseño de una base de datos de red. Este modelo se basa en representaciones entre registros por medio de ligas, existen relaciones en las que participan solo dos entidades (binarias) y relaciones en las que participan más de dos entidades (generales) ya sea con o sin atributo descriptivo en la relación.
La forma de diagramado consta de dos componentes básicos:
Celdas: representan a los campos del registro.
Líneas: representan a los enlaces entre los registros.
Su representación gráfica se basa en el acomodo de los campos de un registro en un conjunto de celdas que se ligan con otros registros.
ALGORITMOS
Es un conjunto de reglas que permiten obtener un resultado determinado a partir de ciertas reglas definidas.
Algoritmo.- Es una secuencia finita de instrucciones, cada una de las cuales tiene un significado preciso y puede ejecutarse con una cantidad finita de esfuerzo en un tiempo finito. Ha de tener las siguientes características: Legible, correcto, modular, eficiente, estructurado, no ambiguo y a ser posible se ha de desarrollar en el menor tiempo posible.
Características de un algoritmo de computador:
1.-Correcto2.-Legible3.-eficiente4.-Diseño de algoritmos.
Fases:Diseño: se dan las especificaciones en lenguaje natural y se crea un primer modelo matemático apropiado. La solución en esta etapa es un algoritmo expresado de manera muy informal.
Implementación: El programador convierte el algoritmo en código, siguiendo alguna de estas 3 metodologías.
TOP-DOWN se alcanza el programa sustituyendo las palabras de las palabras del pseudocódigo por secuencias de proposiciones cada vez más detalladas, en un llamado refinamiento progresivo.
BOTTON-UP parte de las herramientas más primitivas hasta que se llega al programa.Pruebas: Es un material que se pasa al programa para detectar posibles errores. Esto no quiere decir que el diseño no tenga errores, puede tenerlos para otros datos.
ORGANIZACIÓN MODULAR
Son ensambladores que aparecieron como respuesta a una nueva arquitectura de procesadores de 32 bits, muchos de ellos teniendo compatibilidad hacia atrás pudiendo trabajar con programas con estructuras de 16 bits. Además de realizar la misma tarea que los anteriores, permitiendo también el uso de macros, permiten utilizar estructuras de programación más complejas propias de los lenguajes de alto nivel.
PROCESAMIENTOS DE TABLAS: BUSQUEDA Y CLASIFICACION
BUSQUEDA LINEAL
La búsqueda lineal probablemente es sencilla de implementar e intuitiva. Básicamente consiste en buscar de manera secuencial un elemento, es decir, preguntar si el elemento buscado es igual al primero, segundo, tercero y así sucesivamente hasta encontrar el deseado. Entonces este algoritmo tiene una complejidad de O(n).
BUSQUEDA BINARIA
La búsqueda binaria al igual que otros algoritmos como el quicksort utiliza la técnica divide y vencerás. Uno de los requisitos antes de ejecutar la búsqueda binaria, es que el conjunto de elementos debe de estar ordenado. Supongamos que tenemos el siguiente array.
57 53 21 37 17 36 22 3 44 97 89 26 31 47 8 17
Debemos ordenarlo
3 8 17 17 21 22 26 31 36 37 44 47 53 57 89 97
CLASIFICACION
ENSAMBLADORES CRUZADOS: permiten el soporte de medios físicos como pantallas, impresoras, teclado, etc. y la programación que ofrecen maquinas potentes que luego serán ejecutados en sistemas especializados.
ENSAMBLADORES RESIDENTES: permanecen en la memoria de la computadora, y cargan para su ejecución al programa objeto producido. Es el indicado para el desarrollo de pequeños sistemas de control.
MACROENSAMBLADORES: permiten el uso de macroinstrucciones, son programas grandes que no permanecen en memoria una vez que se ha generado el código objeto, normalmente son programas complejos y residentes.
MICROENSAMBLADORES: Indica al interprete las instrucciones de cómo debe actuar la CPU.
ENSAMBLADORES DE UNA FASE: leen una línea de programa fuente y la traducen directamente para producir una instrucción en lenguaje máquina, estos ensambladores son sencillos, baratos y ocupan poco espacio.
ENSAMBLADORES DE DOS FASES: se llaman así por que realizan la traducción en dos etapas, en la primera fase revisan el código fuente y lo construyen en una tabla de símbolos, en la segunda fase vuelven a leer el programa fuente y pueden tardar por completo. Estos ensambladores son los más utilizados en la actualidad.
MACROLENGUAJES Y MACROPROCESADORES
MACROINSTRUCCIONES
Una macroinstrucción o macro, se refiere en el mundo de la informática a una instrucción en lenguaje ensamblador que es equivalente a otro grupo de instrucciones que, en conjunto, realizan una tarea más compleja.
Esta equivalencia es definida por el programador con objeto de simplificar la tarea de escribir programas y reutilizar el código escrito. Este concepto es similar al de la subrutina pero se diferencia de ésta en su funcionamiento. Una macroinstrucción que aparece en un fichero fuente, es sustituida por el programa ensamblador en el fichero objeto por el grupo de instrucciones en lenguaje ensamblador que se han definido. Esta acción se denomina comúnmente expandir la macro.
CARACTERISTICAS
Un macroinstrucción es por tanto una instrucción compleja, formada por otras instrucciones más sencillas.
Además tiene que estar almacenada, el término no se aplica a una serie de instrucciones escritas en la línea de comandos enlazadas unas con otras por redirección de sus resultados o para su ejecución consecutiva.
La diferencia entre un macroinstrucción y un programa es que en las macroinstrucciones la ejecución es secuencial y no existe otro concepto del flujo de programa que por tanto, no puede bifurcarse.
MACROS EN PROGRAMACION
Con el fin de evitar al programador la tediosa repetición de partes idénticas de un programa, los ensambladores y compiladores cuentan con macro procesadores que permiten definir una abreviatura para representar una parte de un programa y utilizar esa abreviatura cuantas veces sea necesario. Para utilizar una macro, primero hay que declararla. En la declaración se establece el nombre que se le dará a la macro y el conjunto de instrucciones que representará.
El programador escribirá el nombre de la macro en cada uno de los lugares donde se requiera la aplicación de las instrucciones por ella representadas. La declaración se realiza una sola vez, pero la utilización o invocación a la macro (macro llamada) puede hacerse cuantas veces sea necesario. La utilización de macros posibilita la reducción del tamaño del código fuente, aunque el código objeto tiende a ser mayor que cuando se utilizan funciones.

PARTICULARIDADES DE LOS MACROS
El lenguaje ensamblador es la forma más básica de programar un microprocesador para que éste sea capaz de realizar las tareas o los cálculos que se le requieran.El lenguaje ensamblador es conocido como un lenguaje de bajo nivel, esto significa que nos permite controlar el 100 % de las funciones de un microprocesador, así como los periféricos asociados a éste.
A diferencia de los lenguajes de alto nivel, por ejemplo "Pascal", el lenguaje ensamblador no requiere de un compilador, esto es debido a que las instrucciones en lenguaje ensamblador son traducidas directamente a código binario y después son colocadas en memoria para que el microprocesador las tome directamente.Aprender a programar en lenguaje ensamblador no es fácil, se requiere un cierto nivel de conocimiento de la arquitectura y organización de las computadoras, además del conocimiento de programación en algún otro lenguaje
Ventajas del lenguaje ensamblador:
-
Velocidad de ejecución de los programas
-
Mayor control sobre el hardware de la computadora
Desventajas del lenguaje ensamblador:
-
Repetición constante de grupos de instrucciones
-
No existe una sintaxis estandarizada
-
Dificultad para encontrar errores en los programas (bugs)
ARGUMENTOS DE MACROINSTRUCCION
Permite una sustitución de texto parametreado por argumentos
#define símbolo (a1, a2, ...) cadena-caracteres
-
El símbolo y el ( deben estar pegados
-
La cadena en general depende de los argumentos a1, a2, ...
-
símbolo(x,y,...) es reemplazado por la cadena en la cual todos las ocurrencias de los argumentos formales: a1, a2,... son reemplazados por argumentos efectivos x,y,...
-
La cadena puede estar vacía, (mismo efecto que antes).
#define max (a, b) ((a)? (B)? (a) : (b) )
Con esta definición la línea:
x = Max (58, x*y);
Es sustituida por:
x = ( (58)? (x*y) ? 58: (x*y) );
Si no se utilizan los paréntesis puede generarse algo incorrecto:
#define cuadrado(a) (a*a)
...
x = cuadrado (y+1);
Es transformado en:
x= (y+1*y+1); es decir x =2*y+1
EXPANSIÓN CONDICIONAL DE MACROS
En esta unidad se estudian el diseño y la construcción de los procesadores de macros. Una macroinstrucción (abreviada cómo macro) no es más que una conveniencia notaciones para el programador.
Una macro representa un grupo de proposiciones utilizadas comúnmente en el lenguaje de programación fuente. El procesador de macros reemplaza cada macroinstrucción con el grupo de correspondiente de proposiciones del lenguaje fuente, lo que se denomina expansión de las macros.
De esta forma, los macroinstrucciones permiten al programador escribir una versión abreviada de un programa, dejando que el procesador de macros maneja los detalles mecánicos.
En esencia, las funciones de un procesador de macros implican la sustitución de un grupo de caracteres o líneas por otras. Con excepción de unos cuantos casos especializados, el procesador de macros no realiza ningún análisis de texto que maneja. El diseño y posibilidades de un procesador de macros pueden estar influidos por la forma de las proposiciones del lenguaje de programación.
MACROLLAMADAS DENTRO DE MACROINSTRUCCIONES
Es una serie de instrucciones que se almacenan para que se puedan ejecutar de manera secuencial mediante una sola llamada u orden de ejecución. Dicho de otra manera, un macroinstrucción es una instrucción compleja, formada por otras instrucciones más sencillas. Esto permite la automatización de tareas repetitivas.
Las macros tienden a almacenarse en el ámbito del propio programa que las utiliza y se ejecutan pulsando una combinación especial de teclas o un botón especialmente creado y asignado para tal efecto.
La diferencia entre un macroinstrucción y un programa es que en los macroinstrucciones la ejecución es secuencial y no existe otro concepto del flujo de programa, y por tanto, no puede bifurcarse.
MACROINSTRUCCIONES QUE DEFINEN MACROS
RP-aaa-bb-ccaaa
Es el tipo de macroinstrucción:
IMP Macroinstrucción de importación
EXP Macroinstrucción de exportación
bb es la tabla de base de datos en la que se graban los datos:
C1 Objeto de base de datos PCL1
C2 Objeto de base de datos PCL2
C3 Objeto de base de datos PCL3
C4 Objeto de base de datos PCL4
cc es el cluster:
RX Objeto de cluster RX
RD Objeto de cluster RD
B2 Objeto de cluster B2
etc.
Las macros se definen usando los comandos ABAP DEFINE/END-OF-DEFINITION
IMPLEMENTACION RESTRINGIDA. ALGORITMO DE DOS PASOS
Los algoritmos pueden ser expresados de muchas maneras, incluyendo al lenguaje natural, pseudocódigo, diagramas de flujo y lenguajes de programación entre otros.
Las descripciones en lenguaje natural tienden a ser ambiguas y extensas. El usar pseudocódigo y diagramas de flujo evita muchas ambigüedades del lenguaje natural.
Dichas expresiones son formas más estructuradas para representar algoritmos; no obstante, se mantienen independientes de un lenguaje de programación específico.
La descripción de un algoritmo usualmente se hace en tres niveles:
-
Descripción de alto nivel. Se establece el problema, se selecciona un modelo matemático y se explica el algoritmo de manera verbal, posiblemente con ilustraciones y omitiendo detalles.
-
Descripción formal. Se usa pseudocódigo para describir la secuencia de pasos que encuentran la solución.
-
Implementación. Se muestra el algoritmo expresado en un lenguaje de programación específico o algún objeto capaz de llevar a cabo instrucciones.
También es posible incluir un teorema que demuestre que el algoritmo es correcto, un análisis de complejidad o ambos.
IMPLEMENTACION DE MACROLLADAMAS DENTRO DE MACROS
Una macroinstrucción puede ser de la biblioteca del sistema o generada por el programador. En ambos casos, la definición del macroinstrucción consta de una pseudo-instrucción de cabecera o de nombre de la macro y de un conjunto de instrucciones en lenguaje ensamblador o cuerpo de la macro.
La operación de sustituir el macroinstrucción por el conjunto correspondiente de instrucciones recibe el nombre de expansión del macroinstrucción.
Cuando un macroensamblador encuentra un «nombre de macro», introduce (durante el paso primero, gracias a una bifurcación) el nombre y el cuerpo en una tabla llamada tabla de definición de macros.
Durante el segundo paso cuando separa el campo de operación, busca primero el símbolo en la tabla de definición de macros. Si no lo encuentra, procede como en un ensamblador; pero si lo encuentra, el macroensamblador bifurca a la tabla y procesa la expansión de la macro, sustituyendo los parámetros formales que tenía la tabla por los parámetros de la instrucción.
ESQUEMA DE CARGA
Un cargador es la parte de un sistema operativo que es responsable de cargar programas en memoria desde los ejecutables (por ejemplo, USB y cd). El cargador es usualmente una parte del núcleo del sistema operativo y es cargado al iniciar el sistema y permanece en memoria hasta que el sistema es reiniciado o apagado. Algunos sistemas operativos que tienen un núcleo paginable pueden tener el cargador en una parte paginable de la memoria, entonces a veces el cargador hace un intercambio de memoria.
Todos los sistemas operativos que soportan la carga de programas tienen cargadores. Algunos sistemas operativos empotrados de computadoras altamente especializadas corren un único programa y no existen capacidades de carga de programas, por lo tanto no usan cargadores.
CARGADORES “COMPILE YTRANSFERENCIA”
Consiste en juntar en un mismo espacio de direcciones módulos que han sido compilados por aparte y resolver las referencias externas entre ellos.
El encadenamiento se puede realizar:
Al compilar: por ejemplo al utilizar las directivas de compilación #include en C, o uses en Pascal. En este caso el sistema operativo no se ve directamente involucrado en el proceso pues este es responsabilidad del compilador.
Después de compilar y antes de cargar: Cuando se tiene después de compilación un programa.obj y para su ejecución es necesario convertirlo en .exe. En estos casos se recurre a programas que se encargan de realizar el proceso, como por ejemplo link, plink86, etc.
Durante la ejecución. Es el caso del llamado a librerías del tipo .dll (dynamic link library) de Windows, en donde el encadenamiento se realiza durante el tiempo de ejecución.
Carga
La carga consiste en colocar un programa en memoria para que pueda ser ejecutado. Existen diferentes tipos de cargadores:
Compile and go: (compile y execute). Son los utilizados por los compiladores tipo Turbo (Pascal, C, Prolog, etc.), que realizan todas las etapas enumeradas previamente, cuando la compilación se realiza directamente a la memoria. La idea central consiste en que a medida que se va compilando se va escribiendo directamente sobre la memoria el código ejecutable y una vez se termine el proceso, se le da el control al programa compilado para su ejecución.
Cargadores Absolutos: Existen en sistemas en los que los compiladores generan código absoluto (no relocalizarla). De esta forma se obliga a que el programa siempre se deba carga en las mismas posiciones de memoria. Son relativamente simples pero no permiten tener multiprogramación.
Cargadores Relocalizados: permiten cargar el programa en cualquier sitio de la memoria. Para que esto sea posible, es necesario contar con algún mecanismo de relocalización.
Cargadores Dinámicos: Cargan los procedimientos del programa dinámicamente durante su ejecución. Son necesarios en el caso de presentarse recubrimientos.
Cargadores en memoria virtual.
CARGADORES ABSOLUTOS
Como ya se mencionó, el programa cargador pone en memoria las instrucciones guardadas en sistemas externos. Si dichas instrucciones se almacenan siempre en el mismo espacio de memoria (cada vez que se ejecute el programa cargador), se dice que es un cargador absoluto.
5.1.4.- ENCADENAMIENTO DE SUBRUTINAS
Consiste en juntar en un mismo espacio de direcciones módulos que han sido compilados por aparte y resolver las referencias externas entre ellos.
Tipo de encadenamiento al compilar, por ejemplo al utilizar las directivas de compilación #include en lenguaje C o uses en PASCAL.
En este caso el Sistema Operativo no se ve directamente involucrado en el proceso pues este es responsabilidad del compilador.
CARGADORES
Un cargador es un programa del sistema que realiza la función de carga, pero muchos cargadores también incluyen relocalización y ligado. Algunos sistemas tienen un ligador para realizar las operaciones de enlace, y un cargador separado para manejar la relocalización y la carga. Los procesos de ensamblado y carga están íntimamente relacionados.
Las funciones más importantes de un cargador son: colocar un programa objeto en la memoria e iniciar su ejecución. Si tenemos un cargador que no necesita realizar las funciones de ligado y relocalización de programas, su operación es muy simple, pues todas las funciones se realizan en un solo paso. Se revisa el registro de encabezamiento para comprobar se ha presentado el programa correcto para la carga (entrando en la memoria disponible). A medida que se lee cada registro de texto, el código objeto que contiene pasa a la dirección de memoria indicada. Cuando se encuentra el registro de fin, el cargador salta a la dirección especificada para iniciar la ejecución del programa cargado.
Un programa objeto contiene instrucciones traducidas y valores de datos del programa fuente, y específica direcciones en memoria donde se cargarán estos elementos.
Carga, que lleva el programa objeto a la memoria para su ejecución.
Relocalización, que modifica el programa objeto de forma que puede cargarse en una dirección diferente de la localidad especificada originalmente.
OTROS SISTEMAS DE CARGA
Un cargador de arranque (“bootloader" en inglés) es un programa sencillo (que no tiene la totalidad de las funcionalidades de un sistema operativo) diseñado exclusivamente para preparar todo lo que necesita el sistema operativo para funcionar. Normalmente se utilizan los cargadores de arranque multietapas, en los que varios programas pequeños se suman los unos a los otros, hasta que el último de ellos carga el sistema operativo.
En los ordenadores modernos, el proceso de arranque comienza con la CPU ejecutando los programas contenidos en la memoria ROM en una dirección predefinida (se configura la CPU para ejecutar este programa, sin ayuda externa, al encender el ordenador).
ESPECIFICACION DE LA ESTRUCTURA DE DATOS
Una estructura de Datos es una colección de datos que pueden ser caracterizados por su organización y las operaciones que se definen en ella.
Los tipos de datos más frecuentes utilizados en los diferentes lenguajes de programación son:
Para ver el gráfico seleccione la opción "Descargar" del menú superior
Los tipos de datos simples pueden ser organizados en diferentes estructuras de datos: estáticas y dinámicas.
Las estructuras de datos estáticas:
Son aquellas en las que el tamaño ocupado en memoria se define antes de que el programa se ejecute y no puede modificarse dicho tamaño durante la ejecución del programa.
Estas estructuras están implementadas en casi todos los lenguajes.
Su principal característica es que ocupan solo una casilla de memoria, por lo tanto una variable simple hace referencia a un único valor a la vez, dentro de este grupo de datos se encuentra: enteros, reales, caracteres, boléanos, enumerados y subrangos (los últimos no existen en algunos lenguajes de programación)
Las estructuras de datos dinámicas:
No tienen las limitaciones o restricciones en el tamaño de memoria ocupada que son propias de las estructuras estáticas.
Mediante el uso de un tipo de datos especifico, denominado puntero, es posible construir estructuras de datos dinámicas que no son soportadas por la mayoría de los lenguajes, pero que en aquellos que si tienen estas características ofrecen soluciones eficaces y efectivas en la solución de problemas complejos.
Se caracteriza por el hecho de que con un nombre se hace referencia a un grupo de casillas de memoria. Es decir un dato estructurado tiene varios componentes.
FORMATO DE LA BASE DE DATOS
Una base de datos o banco de datos es un conjunto de datos pertenecientes a un mismo contexto y almacenados sistemáticamente para su posterior uso. En este sentido, una biblioteca puede considerarse una base de datos compuesta en su mayoría por documentos y textos impresos en papel e indexados para su consulta. Actualmente, y debido al desarrollo tecnológico de campos como la informática y la electrónica, la mayoría de las bases de datos están en formato digital (electrónico), y por ende se ha desarrollado y se ofrece un amplio rango de soluciones al problema del almacenamiento de datos.
Existen programas denominados sistemas gestores de bases de datos, abreviado SGBD, que permiten almacenar y posteriormente acceder a los datos de forma rápida y estructurada. Las propiedades de estos SGBD, así como su utilización y administración, se estudian dentro del ámbito de la informática.
Las aplicaciones más usuales son para la gestión de empresas e instituciones públicas. También son ampliamente utilizadas en entornos científicos con el objeto de almacenar la información experimental. Aunque las bases de datos pueden contener muchos tipos de datos, algunos de ellos se encuentran protegidos por las leyes de varios países.

ALGORITMOS
Conjunto ordenado y finito de operaciones que permite hallar la solución de un problema. Método y notación en las distintas fórmulas del cálculo. El algoritmo constituye un método para resolver un problema mediante una secuencia de pasos a seguir. Dicha secuencia puede ser expresada en forma de diagrama de flujo con el fin de seguirlo de una forma más sencilla.
De acuerdo con el concepto anterior, el algoritmo podría estar incluido en la definición de programa de ordenador de la Ley de Propiedad Intelectual (TRLPI), al referirse a éste como toda secuencia de instrucciones o indicaciones destinadas a ser utilizadas, directa o indirectamente, en un sistema informático para realizar una función o una tarea o para obtener un resultado determinado, cualquiera que fuere su forma de expresión y fijación.
LENGUAJES DE LA PROGRAMACION
Un lenguaje de programación es un idioma artificial diseñado para expresar procesos que pueden ser llevados a cabo por máquinas como lascomputadoras.
Pueden usarse para crear programas que controlen el comportamiento físico y lógico de una máquina, para expresar algoritmos con precisión, o como modo de comunicación humana.1
Está formado por un conjunto de símbolos y reglas sintácticas y semánticas que definen su estructura y el significado de sus elementos y expresiones. Al proceso por el cual se escribe, se prueba, se depura, se compila y se mantiene el código fuente de un programa informático se le llama programación.
También la palabra programación se define como el proceso de creación de un programa de computadora, mediante la aplicación de procedimientos lógicos, a través de los siguientes pasos:
· El desarrollo lógico del programa para resolver un problema en particular.
· Escritura de la lógica del programa empleando un lenguaje de programación específico (codificación del programa).
· Ensamblaje o compilación del programa hasta convertirlo en lenguaje de máquina.
· Prueba y depuración del programa.
· Desarrollo de la documentación.
Existe un error común que trata por sinónimos los términos 'lenguaje de programación' y 'lenguaje informático'. Los lenguajes informáticos engloban a los lenguajes de programación y a otros más, como por ejemplo HTML (lenguaje para el marcado de páginas web que no es propiamente un lenguaje de programación, sino un conjunto de instrucciones que permiten diseñar el contenido de los documentos).
Permite especificar de manera precisa sobre qué datos debe operar una computadora, cómo deben ser almacenados o transmitidos y qué acciones debe tomar bajo una variada gama de circunstancias. Todo esto, a través de un lenguaje que intenta estar relativamente próximo al lenguaje humano o natural. Una característica relevante de los lenguajes de programación es precisamente que más de un programador pueda usar un conjunto común de instrucciones que sean comprendidas entre ellos para realizar la construcción de un programa de forma colaborativa.
IMPORTACION DE LOS LENGUAJES DE ALTO NIVEL
La importancia del lenguaje ensamblador radica principalmente que se trabajadirectamente con el microprocesador; por lo cual se debe de conocer elfuncionamiento interno de este, tiene la ventaja de que en el se puede realizar cualquier tipo de programas que en los lenguajes de alto nivel no lo puedenrealizar. Otro punto sería que los programas en ensamblador ocupan menosespacio en memoria.Permitirá adentrarnos al estudio del hardware de una PC.Este lenguaje proporciona las herramientas para tomar control sobre todo lo que lacomputadora realiza físicamente.Es importante como se puede ver, el Lenguaje Ensamblador es directamentetraducible al Lenguaje de Máquina, y viceversa; simplemente, es una abstracciónque facilita su uso para los seres humanos. Por otro lado, la computadora noentiende directamente al Lenguaje Ensamblador; es necesario traducirle aLenguaje de Máquina. Pero, al ser tan directa la traducción, pronto aparecieron losprogramas Ensambladores, que son traductores que convierten el código fuente(en Lenguaje Ensamblador) a código objeto (es decir, a Lenguaje de Máquina.Surge como una necesidad de facilitar al programador la tarea de trabajar conlenguaje máquina sin perder el control directo con el hardware.VentajasProporciona un control absoluto sobre la PC. Los programas en ensamblador sonrápidos y compactos1. Velocidad.- Como trabaja directamente con el microprocesador al ejecutar unprograma, pues como este lenguaje es el mas cercano a la máquina lacomputadora lo procesa mas rápido.2. Eficiencia de tamaño.- Un programa en ensamblador no ocupa muchoespacio en memoria porque no tiene que cargan librerías y demás como son loslenguajes de alto nivel3. Flexibilidad.- Es flexible porque todo lo que puede hacerse con una máquina,puede hacerse en el lenguaje ensamblador de esta máquina; los lenguajes de altonivel tienen en una u otra forma limitantes para explotar al máximo los recursos dela máquina. O sea que en lenguaje ensamblador se pueden hacer tareasespecificas que en un lenguaje de alto nivel no se pueden llevar acabo porquetienen ciertas limitantes que no se lo permiteUn programa escrito en el lenguaje ensamblador requiere considerablementemenos memoria y tiempo de ejecución que un programa escrito en los conocidoslenguajes de alto nivel, como Pascal y C.El lenguaje ensamblador da a un programador la capacidad de realizar tareasmuy técnicas que serian difíciles, si no es que imposibles de realizar en unlenguaje de alto nivel.El conocimiento del lenguaje ensamblador permite una comprensión de laarquitectura de la maquina que ningún lenguaje de alto nivel puede ofrecer.
DesventajasTiempo de programación .- Como es un lenguaje de bajo nivel requiere másinstrucciones para realizar el mismo proceso, en comparación con un lenguaje dealto nivel. Por otro lado, requiere de más cuidado por parte del programador, pueses propenso a que los errores de lógica se reflejen más fuertemente en laejecución.Programas fuente grandes .- Por las mismas razones que aumenta el tiempo,crecen los programas fuentes; simplemente requerimos más instruccionesprimitivas para describir procesos equivalentes. Esto es una desventaja porquedificulta el mantenimiento de los programas, y nuevamente reduce la productividadde los programadores.Peligro de afectar recursos inesperadamente .- Que todo error que podamoscometer, o todo riesgo que podamos tener, podemos afectar los recursos de lamaquina, programar en este lenguaje lo más común que pueda pasar es que lamáquina se bloquee o se reinicialize. Porque con este lenguaje es perfectamenteposible (y sencillo) realizar secuencias de instrucciones inválidas, quenormalmente no aparecen al usar un lenguaje de alto nivel.Falta de portabilidad.- Porque para cada máquina existe un lenguaje ensamblador;por ello, evidentemente no es una selección apropiada de lenguaje cuandodeseamos codificar en una máquina y luego llevar los programas a otros sistemasoperativos o modelos de computadoras.
PECULIARIDADES DE UN LENGUAJE DE ALTO NIVEL
Se encuentran totalmente vinculados a la estructura del computador.
 Están diseñados para sacar el máximo partido de las características físicas del
computador.
 Características:
•Dependencia absoluta de la arquitectura del computador.
•Imposibilidad de transportar programas entre distintas máquinas, salvo que
sean de la misma familia o compatibles.
•Instrucciones poco potentes.
•Programas muy largos.
•Códigos de operación, datos y referencias en binario.
 Tipos:
•Lenguaje máquina.
Códigos de operación, datos y referencias en binario.
Directamente interpretable y ejecutable por la circuitería del computador.
•Lenguaje ensamblador.
6.3 tipos de datos y estructura de datos
6.3.1 series de caracteres
Una serie de caracteres es una secuencia de bytes. La longitud de la serie es el número de bytes en la secuencia. Si la longitud es cero, el valor se denomina la serie vacía. Este valor no debe confundirse con el valor nulo.Serie de caracteres de longitud fija (CHAR)Todos los valores de una columna de series de longitud fija tienen la misma longitud, que está determinada por el atributo de longitud de la columna. El atributo de longitud debe estar entre 1 y 254, inclusive.Series de caracteres de longitud variableExisten dos tipos de series de caracteres de longitud variable:
Un valor VARCHAR puede tener una longitud máxima de 32.672 bytes.
Un valor CLOB (objeto grande de caracteres) puede tener una longitud máxima de 2 gigabytes menos 1 byte (2.147.483.647 bytes). Un CLOB se utiliza para almacenar datos basados en caracteres SBCS o mixtos (SBCS y MBCS) (como, por ejemplo, documentos grabados con un solo juego de caracteres) y, por lo tanto, tiene una página de códigos SBCS o mixta asociada).
Se aplican restricciones especiales a las expresiones que dan como resultado un valor de tipo de datos CLOB y a columnas de tipo estructurado; estas expresiones y columnas no se permiten en:
Una lista SELECT precedida por la cláusula DISTINCT
Una cláusula GROUP BY
Una cláusula ORDER BY
Una subselección de un operador de conjunto que no sea UNION ALL
Un predicado BETWEEN o IN básico y cuantificado
Una función agregada
Las funciones escalares VARGRAPHIC, TRANSLATE y de fecha y hora
El operando patrón de un predicado LIKE o el operando de serie de búsqueda de una función POSSTR
La representación en una serie de un valor de fecha y hora.
Las funciones del esquema SYSFUN que toman VARCHAR como argumento no aceptarán las VARCHAR que tengan más de 4.000 bytes de longitud como argumento. Sin embargo, muchas de estas funciones también pueden tener una signatura alternativa que acepte un CLOB (1M). Para estas funciones, el usuario puede convertir explícitamente las series VARCHAR mayores que 4.000 en datos CLOB y, a continuación, volver a convertir el resultado en datos VARCHAR de la longitud deseada.Las series de caracteres terminadas en nulo que se encuentran en C se manejan de manera diferente, dependiendo del nivel de estándares de la opción de precompilación.Cada serie de caracteres se define con más detalle como:Datos de bit: Datos que no están asociado con una página de códigos.Datos de juego de caracteres de un solo byte (SBCS): Datos en los que cada carácter está representado por un solo byte.Datos mixtos: Datos que pueden contener una mezcla de caracteres de un juego de caracteres de un solo byte y de un juego de caracteres de múltiples bytes (MBCS).Nota: El tipo de datos LONG VARCHAR sigue estando soportado pero ha quedado obsoleto, no es recomendable y puede eliminarse en un release futuro.
SERIES DE BITS
El método más sencillo de representación son los números naturales. Por ejemplo, si tengo el número 85 en decimal, solo tengo que llevarlo a binario y obtengo una serie de unos y ceros:1010101 = 85 en binarioCada dígito (un cero o un uno) de este número se llama bit. Java tiene una serie de operadores capaces de manipular estos dígitos, son los operadores de bits.Para operar a nivel de bit es necesario tomar toda la longitud predefinida para el tipo de dato. Estamos acostumbrados a desechar los ceros a la izquierda en nuestra representación de números. Pero aquí es importante. Si trabajamos una variable de tipo short con un valor de 3, está representada de la siguiente manera:0000000000000011Aquí los 16 bits de un short se tienen en cuenta.
OPERADORES BOLEANOS
Los operadores booleanos (AND, NOT, OR, XOR) localizan registros que contienen los términos coincidentes en uno de los campos especificados o en todos los campos especificados. Utilizar operadores booleanos para conectar palabras o frases entre más de un campo de texto, o utilizar operadores booleanos para conectar palabras o frases dentro de un campo de texto.
Utilizar el operador AND para localizar registros que contengan todos los términos de búsqueda especificados. Por ejemplo, si se busca por "perros AND gatos", la biblioteca-e localiza registros que contengan todos los términos especificados.
Utilizar el operador OR para localizar registros que contengan cualquiera o todos los términos especificados. Por ejemplo, si se busca por "perros OR gatos", la biblioteca-e localiza registros que contengan el primer término o el segundo.
Utilizar el operador NOT para localizar registros que contengan el primer término de búsqueda pero no el segundo. Por ejemplo, si se busca por "perros NOT gatos", la biblioteca-e localiza registros que contienen el primer término pero no el segundo.
Utilizar el operador XOR (o exclusivo) para localizar registros que contengan cualquiera de los términos especificados pero no todos los términos especificados. Por ejemplo, si se busca por "perros XOR gatos", la biblioteca-e localiza registros que contienen cualquiera de los términos especificados pero no todos los términos especificados.
ESTRUCTURA DE DATOS
Una estructura de datos es una forma de organizar un conjunto de datos elementales con el objetivo de facilitar su manipulación. Un dato elemental es la mínima información que se tiene en un sistema.Una estructura de datos define la organización e interrelación de estos y un conjunto de operaciones que se pueden realizar sobre ellos. Las operaciones básicas son:
Alta, adicionar un nuevo valor a la estructura.
Baja, borrar un valor de la estructura.
Búsqueda, encontrar un determinado valor en la estructura para realizar una operación con este valor, en forma secuencial o binario (siempre y cuando los datos estén ordenados).
Otras operaciones que se pueden realizar son:
Ordenamiento, de los elementos pertenecientes a la estructura.
Apareo, dadas dos estructuras originar una nueva ordenada y que contenga a las apareadas.
Cada estructura ofrece ventajas y desventajas en relación a la simplicidad y eficiencia para la realización de cada operación. De esta forma, la elección de la estructura de datos apropiada para cada problema depende de factores como la frecuencia y el orden en que se realiza cada operación sobre los datos.
ASIGNACIÓN DE ALMACENAMIENTO Y ALCANCE DE NOMBRES
CLASE DE ALMACENAMIENTO
Existen los modificadores de tipo o clases de almacenamiento que permiten modificar el ámbito y la permanencia de una variable dentro de un programa. Existen cuatro modificadores de tipo, automático, externo, estático y registró, que se corresponden con las palabras reservadas auto, extern, static y register, respectivamente.
ESTRUCTURA DE DATOS
El diagrama de bloques es la representación gráfica del funcionamiento interno de un sistema, que se hace mediante bloques y sus relaciones, y que, además, definen la organización de todo el proceso interno, sus entradas y sus salidas.Un diagrama de bloques de procesos de producción es un diagrama utilizado para indicar la manera en la que se elabora cierto producto alimenticio, especificando la materia prima, la cantidad de procesos y la forma en la que se presenta el producto terminado.Un diagrama de bloques de modelo matemático es el utilizado para representar el control de sistemas físicos (o reales) mediante un modelo matemático, en el cual, intervienen gran cantidad de variables que se relacionan en todo el proceso de producción. El modelo matemático que representa un sistema físico de alguna complejidad conlleva a la abstracción entre la relación de cada una de sus partes, y que conducen a la pérdida del concepto global. En ingeniería de control, se han desarrollado una representación gráfica de las partes de un sistema y sus interacciones. Luego de la representación gráfica del modelo matemático, se puede encontrar la relación entre la entrada y la salida del proceso del sistema.
FLEXIBILIDAD DE ACCESO
El indicador de programación se usa para definir si hay que ejecutar el programa del ciclo de fabricación para el cálculo de fechas extremas (fechas planificadas) para materiales fabricados en la empresa. El programa del ciclo de fabricación calcula las fechas de inicio y final para la fabricación. El sistema sólo crea la necesidad de capacidad si se ha ejecutado el programa del ciclo de fabricación.
PROCEDIMIENTOS
La modularidad es generalmente deseable, sobre todo en programas grandes y complejos. Las entradas se suelen especificar sintácticamente en forma de argumentos y los resultados entregados como valores de retorno.Alcance es otra técnica que ayuda a mantener los procedimientos fuertemente modulares. Evita que el procedimiento de acceso a las variables de otros procedimientos, incluyendo los casos anteriores de sí mismo, sin la autorización explícita.Los procedimientos menos modulares, a menudo usados en los programas de pequeñas o escritas rápidamente, tienden a interactuar con un gran número de variables en el entorno de ejecución, que otros procedimientos también se pueden modificar.Debido a la posibilidad de especificar una interfaz simple, para ser autónomo, y para ser reutilizados, los procedimientos son un vehículo ideal para hacer piezas de código escritas por diferentes personas o en diferentes grupos, incluyendo a través de bibliotecas de programación.
RECLUSIÓN
El objetivo es conseguir lenguajes expresivos y matemáticamente elegantes, en los que no sea necesario bajar al nivel de la máquina para describir el proceso llevado a cabo por el programa, y evitar el concepto de estado del cómputo. La secuencia de computaciones llevadas a cabo por el programa se rige única y exclusivamente por la reescritura de definiciones más amplias a otras cada vez más concretas y definidas, usando lo que se denominan "definiciones dirigidas".
SEÑALES
La E/S asíncrona envía la señal SIGIO al proceso de usuario cuando ocurre el evento de E/S. En este caso esto significa cuando la gente mueve el ratón. La señal SIGIO
RECONOCIMIENTO DE LOS ELEMENTOS BÁSICOS
La construcción de un compilador involucra la división del proceso en una serie de fases que variará con su complejidad. Generalmente estas fases se agrupan en dos tareas: el análisis del programa fuente y la síntesis del programa objeto.
Análisis: Se trata de la comprobación de la corrección del programa fuente, e incluye las fases correspondientes al Análisis léxico (que consiste en la descomposición del programa fuente en componentes léxicos), Análisis sintáctico (agrupación de los componentes léxicos en frases gramaticales) y Análisis semántico (comprobación de la validez semántica de las sentencias aceptadas en la fase de Análisis Sintáctico).
Síntesis: Su objetivo es la generación de la salida expresada en el lenguaje objeto y suele estar formado por una o varias combinaciones de fases de Generación de Código (normalmente se trata de código intermedio o de código objeto) y de Optimización de Código (en las que se busca obtener un código lo más eficiente posible).
Alternativamente, las fases descritas para las tareas de análisis y síntesis se pueden agrupar en Front-end y Back-end:
Front-end: es la parte que analiza el código fuente, comprueba su validez, genera el árbol de derivación y rellena los valores de la tabla de símbolos. Esta parte suele ser independiente de la plataforma o sistema para el cual se vaya a compilar, y está compuesta por las fases comprendidas entre el Análisis Léxico y la Generación de Código Intermedio.
Back-end: es la parte que genera el código máquina, específico de una plataforma, a partir de los resultados de la fase de análisis, realizada por el Front End.
RECONOCIMIENTO DE LAS UNIDADES SINTÁCTICAS E INTERPRETACIÓN DEL SIGNIFICADO
En esta fase los caracteres o componentes léxicos se agrupan jerárquicamente en frases gramaticales que el compilador utiliza para sintetizar la salida. Se comprueba si lo obtenido de la fase anterior es sintácticamente correcto (obedece a la gramática del lenguaje). Por lo general, las frases gramaticales del programa fuente se representan mediante un árbol de análisis sintáctico.La estructura jerárquica de un programa normalmente se expresa utilizando reglas recursivas. Por ejemplo, se pueden dar las siguientes reglas como parte de la definición de expresiones:
Cualquier identificador es una expresión.
Cualquier número es una expresión.
Si expresión y expresión son expresiones, entonces también lo son:
expresión + expresión
expresión * expresión
(expresión )
Las reglas 1 y 2 son reglas básicas (no recursivas), en tanto que la regla 3 define expresiones en función de operadores aplicados a otras expresiones.La división entre análisis léxico y análisis sintáctico es algo arbitraria. Un factor para determinar la división es si una construcción del lenguaje fuente es inherentemente recursiva o no. Las construcciones léxicas no requieren recursión, mientras que las construcciones sintácticas suelen requerirla. No se requiere recursión para reconocer los identificadores, que suelen ser cadenas de letras y dígitos que comienzan con una letra. Normalmente, se reconocen los identificadores por el simple examen del flujo de entrada, esperando hasta encontrar un carácter que no sea ni letra ni dígito, y agrupando después todas las letras y dígitos encontrados hasta ese punto en un componente léxico llamado identificador. Por otra parte, esta clase de análisis no es suficientemente poderoso para analizar expresiones o proposiciones. Por ejemplo, no podemos emparejar de manera apropiada los paréntesis de las expresiones, o las palabras begin y end en proposiciones sin imponer alguna clase de estructura jerárquica o de anidamiento a la entrada.
FORMAS INTERMEDIAS GENERACION CODIGO INTERMEDIO:
Los compiladores deben analizar y generar secuencias de instrucciones iguales a un programa fuente con el fin de aprovechar mucho mas la memoria del equipo, en esta etapa se genera un código con el fin de que este sea optimizando en la siguiente etapa.
FASE LÉXICA
El análisis léxico constituye la primera fase, aquí se lee el programa fuente de izquierda a derecha y se agrupa en componentes léxicos (tokens), que son secuencias de caracteres que tienen un significado. Además, todos los espacios en blanco, líneas en blanco, comentarios y demás información innecesaria se elimina del programa fuente. También se comprueba que los símbolos del lenguaje (palabras clave, operadores, etc.) se han escrito correctamente.Como la tarea que realiza el analizador léxico es un caso especial de coincidencia de patrones, se necesitan los métodos de especificación y reconocimiento de patrones, se usan principalmente los autómatas finitos que acepten expresiones regulares. Sin embargo, un analizador léxico también es la parte del traductor que maneja la entrada del código fuente, y puesto que esta entrada a menudo involucra un importante gasto de tiempo, el analizador léxico debe funcionar de manera tan eficiente como sea posible
FASE DE INTERPRETACIÓN
En esta fase los caracteres o componentes léxicos se agrupan jerárquicamente en frases gramaticales que el compilador utiliza para sintetizar la salida. Se comprueba si lo obtenido de la fase anterior es sintácticamente correcto (obedece a la gramática del lenguaje). Por lo general, las frases gramaticales del programa fuente se representan mediante un árbol de análisis sintáctico.
OPTIMIZACIÓN
La fase de optimización de código consiste en mejorar el código intermedio, de modo que resulte un código máquina más rápido de ejecutar. Esta fase de la etapa de síntesis es posible sobre todo si el traductor es un compilador (difícilmente un interprete puede optimizar el código objeto). Hay mucha variación en la cantidad de optimización de código que ejecutan los distintos compiladores. En los que hacen mucha optimización, llamados «compiladores optimizadores», una parte significativa del tiempo del compilador se ocupa en esta fase. Sin embargo, hay optimizaciones sencillas que mejoran sensiblemente el tiempo de ejecución del programa objeto sin retardar demasiado la compilación.
ASIGNACIÓN DEL ALMACENAMIENTO
La asignación de memoria consiste en el proceso de asignar memoria para propósitos espécificos, ya sea en tiempo de compilación o de ejecución. Si es en tiempo de compilación es estática, si es en tiempo de ejecución es dinámica y si son variables locales a un grupo de sentencias se denomina automática.
GENERACIÓN DEL CÓDIGO
Después de los análisis sintáctico y semántico, algunos compiladores generan una representación intermedia explícita del programa fuente. Se puede considerar esta representación intermedia como un programa para una máquina abstracta. Esta representación intermedia debe tener dos propiedades importantes; debe ser fácil de producir y fácil de traducir al programa objeto.La representación intermedia puede tener diversas formas. Existe una forma intermedia llamada «código de tres direcciones» que es como el lenguaje ensamblador de una máquina en la que cada posición de memoria puede actuar como un registro. El código de tres direcciones consiste en una secuencia de instrucciones, cada una de las cuales tiene como máximo tres operandos. Esta representación intermedia tiene varias propiedades:
Primera. Cada instrucción de tres direcciones tiene a lo sumo un operador, además de la asignación, por tanto, cuando se generan estas instrucciones, el traductor tiene que decidir el orden en que deben efectuarse las operaciones.
Segunda. El traductor debe generar un nombre temporal para guardar los valores calculados por cada instrucción.
Tercera. Algunas instrucciones de «tres direcciones» tienen menos de tres operandos, por ejemplo, la asignación.
FASE DE ENSAMBLE
El ensamblador traduce en instrucciones de lenguaje de máquina, empaquetándolas en una forma conocida como programa objeto relocalizable, y almacena el resultado en el archivo objeto. El archivo es un archivo binario cuyos bytes tienen codificados las instrucciones en lenguaje de máquina en vez de caracteres. SI quisiéramos visualizar con un editor de texto, aparecerían solo caracteres especiales.
PASADAS DE UN COMPILADOR
El compilador traduce el archivo texto de entrada al archivo texto, el cual contiene un programa en lenguaje ensamblador. Normalmente, cada declaración en un programa en lenguaje ensamblador describe exactamente una instrucción en lenguaje de máquina de bajo nivel en forma de archivo texto estándar. El lenguaje ensamblador es útil porque permite un lenguaje de salida común para diferentes compiladores para diferentes lenguajes de programación de alto nivel. Por ejemplo, los compiladores de C y Fortran generan archivos de salida en el mismo lenguaje ensamblador.
IMPLEMENTACIÓN
Primero se aplica el ensamblamiento y la propagación de constantes.
Después se reordena el árbol sintáctico hasta obtener la forma normal.
Se inicia la eliminación de las subexpresiones redundantes.
Hay que considerar las asignaciones que pueden convertir una subexpresion redundante en no redundante.
Ejemplo de eliminación de subexpresiones
J=2*D+3D=D*2J=J+D
ALMACENAMIENTO ESTÁTICO
Para especificar este tipo de almacenamiento se usa el especificador static.Sintaxis:static ;static ();Cuando se usa en la declaración de objetos, este especificador hace que se asigne una dirección de memoria fija para el objeto mientras el programa se esté ejecutando. Es decir, su ámbito temporal es total. En cuanto al ámbito de acceso conserva el que le corresponde según el punto del código en que aparezca la declaración.Debido a que el objeto tiene una posición de memoria fija, su valor permanece, aunque se trate de un objeto declarado de forma local, entre distintas reentradas en el ámbito del objeto. Por ejemplo si se trata de un objeto local a una función, el valor del objeto se mantiene entre distintas llamadas a la función. Hay que tener en cuenta que los objetos estáticos no inicializados toman un valor nulo. Por el contrario, si se le da un valor inicial a una variable estática, la asignación sólo afecta a la primera vez que es declarada.Este tipo de almacenamiento se usa con el fin de que las variables locales de una función conserven su valor entre distintas llamadas sucesivas a la misma. Las variables estáticas tienen un ámbito local con respecto a su accesibilidad, pero temporalmente son como las variables externas.Parecería lógico que, análogamente a lo que sucede con el especificador auto, no tenga sentido declarar objetos globales como estáticos, ya que lo son por defecto. Sin embargo, el especificador static tiene un significado distinto cuando se aplica a objetos globales. En ese caso indica que el objeto no es accesible desde otros ficheros fuente del programa.En el caso de las funciones, el significado es el mismo, las funciones estáticas sólo son accesibles desde el fichero en que están declaradas.
ALMACENAMIENTO AUTOMÁTICO
Para especificar el tipo de almacenamiento automático se usa el especificador auto.Sirve para declarar variables automáticas o locales. Es el modificador por defecto cuando se declaran variables u objetos locales, es decir, si no se especifica ningún modificador, se creará una variable automática.Estas variables se crean durante la ejecución, y se elige el tipo de memoria a utilizar en función del ámbito temporal de la variable. Una vez cumplido el ámbito, la variable es destruida. Es decir, una variable automática local de una función se creará cuando sea declarada, y se destruirá al terminar la función. Una variable local automática de un bucle será destruida cuando el bucle termine.Debido a que estos objetos serán creados y destruidos cada vez que sea necesario, usándose, en general, diferentes posiciones de memoria, su valor se perderá cada vez que sean creadas, perdiéndose el valor previo en cada caso. Por supuesto, no es posible crear variables automáticas globales, ya que son conceptos contradictorios.
ALMACENAMIENTO CONTROLADO EXTERNO
Para especificar este tipo de almacenamiento se usa la palabra extern.Sintaxis:extern ;[extern] ();De nuevo tenemos un especificador que se puede aplicar a funciones y a objetos. O más precisamente, a prototipos de funciones y a declaraciones de objetos.Este especificador se usa para indicar que el almacenamiento y valor de una variable o la definición de una función están definidos en otro módulo o fichero fuente. Las funciones declaradas con extern son visibles por todos los ficheros fuente del programa, salvo que (como vimos más arriba) se defina la función como static. El especificador extern sólo puede usarse con objetos y funciones globales. En el caso de las funciones prototipo, el especificador extern es opcional. Las declaraciones de prototipos son externas por defecto. Este especificador lo usaremos con programas que usen varios ficheros fuente, que será lo más normal con aplicaciones que no sean ejemplos o aplicaciones simples.
ALMACENAMIENTO CONTROLADO INTERNO
Para especificar este tipo de almacenamiento se usa el especificador register.Sintaxis:register ;Indica al compilador una preferencia para que el objeto se almacene en un registro de la CPU, si es posible, con el fin de optimizar su acceso, consiguiendo una mayor velocidad de ejecución.Los datos declarados con el especificador register tienen el mismo ámbito que las automáticas. De hecho, sólo se puede usar este especificador con parámetros y con objetos locales.El compilador puede ignorar la petición de almacenamiento en registro, que se acepte o no estará basado en el análisis que realice el compilador sobre cómo se usa la variable.Un objeto de este tipo no reside en memoria, y por lo tanto no tiene una dirección de memoria, es decir, no es posible obtener una referencia a un objeto declarado con el tipo de almacenamiento en registro.Se puede usar un registro para almacenar objetos de tipo char, int, float, punteros. En general, objetos que quepan en un registro.
INTERRUPCIONES
Interrupción (también conocida como interrupción de hardware o petición de interrupción) es una señal recibida por el procesador de un ordenador, indicando que debe "interrumpir" el curso de ejecución actual y pasar a ejecutar código específico para tratar esta situación.Una interrupción es una suspensión temporal de la ejecución de un proceso, para pasar a ejecutar una subrutina de servicio de interrupción, la cual, por lo general, no forma parte del programa (generalmente perteneciente al sistema operativo, o al BIOS). Luego de finalizada dicha subrutina, se reanuda la ejecución del programa.Las interrupciones surgen de las necesidades que tienen los dispositivos periféricos de enviar información al procesador principal de un sistema de computación.
INDICADORES (POINTERS)
El indicador de programación se usa para definir si hay que ejecutar el programa del ciclo de fabricación para el cálculo de fechas extremas (fechas planificadas) para materiales fabricados en la empresa. El programa del ciclo de fabricación calcula las fechas de inicio y final para la fabricación. El sistema sólo crea la necesidad de capacidad si se ha ejecutado el programa del ciclo de fabricación.